よくある質問
混同行列の読み方は?
混同行列 は、学習済み分類器の性能を評価するために使用されます。
行列の構成
- 行 → 予測クラス(モデルが予測したクラス)
- 列 → 実際のクラス(データの正解ラベル)
主要要素
- 対角セル(青色)
正しい予測- 真陽性(True Positive) – 正しく陽性と予測
- 真陰性(True Negative) – 正しく陰性と予測
- 非対角セル(白色)
誤った予測- 偽陽性(False Positive) および 偽陰性(False Negative)
- 多クラスモデルでは、これらのセルはクラス間の混同を示します
周辺情報
- 最下行 → 各クラスの 精度(緑) と エラー率(赤)
- 右下隅 → 全体の モデル精度 と エラー率
軸ラベルの対応
- X 軸の数値は Y 軸のクラスラベルに直接対応します
例:Y 軸に fan-balance (1) が表示されている場合、X 軸の 1 も同じクラスを示します。
データ表示
- 各数値はヒストグラム内の対応するデータセグメントに対応します。
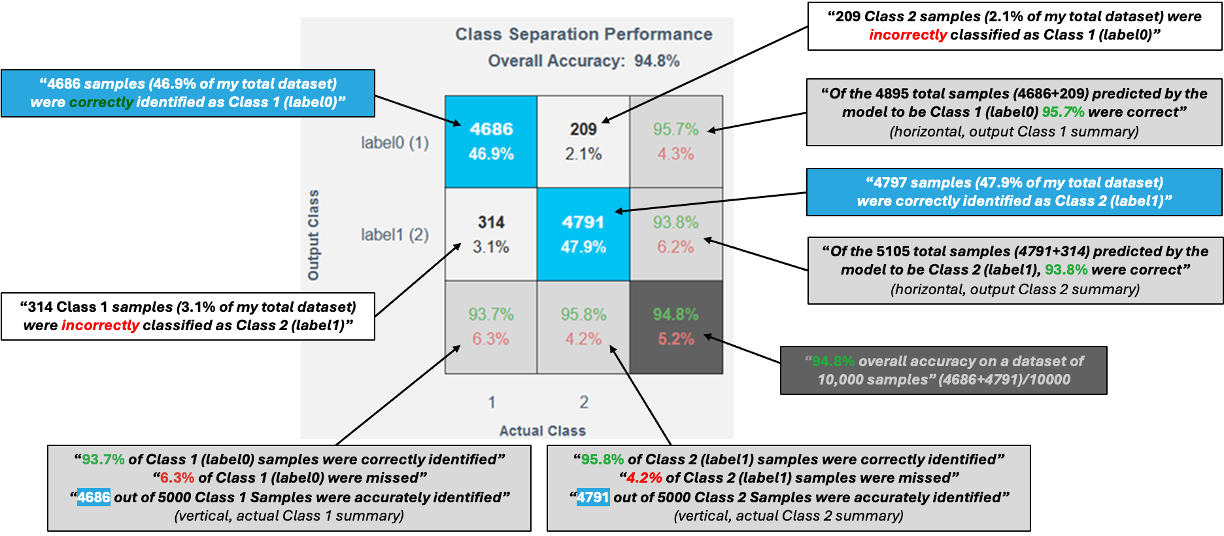
良い混同行列とは何ですか?
良い 混同行列 は通常、次の特徴を示します:
- 非対角(白色)セル の値が非常に小さい
- 対角線 上の値が大きく、正しい予測が多いことを示す
NOTE
混同行列は精度だけでなく、モデルがどこで誤っているかも示すため、モデル改善に非常に有用なツールです。
複雑度数値はどのように解釈すればよいですか?
複雑度数値は、モデルを MCU / MPU に展開した際の リソース使用量 を示します。
- これらの値は 最終値ではありません
- モデルは多くの場合 さらに最適化 できます
例 決定重要度プロットで最も重要な周波数帯が 50 Hz 未満 である場合:
< 50 Hzの周波数のみを使用するフィルターを適用- 特徴量計算を削減
- 乗算処理とメモリ使用量を削減
NOTE
プロジェクト作成時に対象プロセッサを選択している場合、上位モデルはすでにそのプロセッサのリソース制限内に収まっています。
One-vs-One 分類戦略とは何ですか?
One-vs-One は、多クラス分類 で一般的に使用される戦略です。
仕組み
- 各クラスのペア ごとに 1 つの二値分類器を学習
Nクラスの場合 →N(N−1)/2個の分類器が必要
例 クラス A、B、C の場合、モデルは次を学習します:
- A vs B
- A vs C
- B vs C
予測フェーズ
- すべての分類器が並列に実行される
- 投票または集約メカニズム により最終クラスを決定
利点
- 複雑な多クラス問題を単純化
- 精度と解釈性の向上につながる場合が多い
ニューラルネットワークモデルの圧縮はどのように機能しますか?
ニューラルネットワークモデルは、実際に必要なサイズよりも大きく、複雑であることが多くあります。実際のデータで学習する前に、必要なモデルサイズやアーキテクチャを正確に判断することは困難です。
モデル圧縮は、ネットワーク内の冗長または使用率の低い重みを特定して削除することで、この問題に対応します。当社独自の数学的手法を用いてこれらの冗長性を検出し、ネットワークを再構成して、よりシンプルで小さく、かつ高速なモデルにします。
このプロセス全体を通じて、重要な情報が失われないよう、圧縮率と精度のバランスを慎重に調整します。