嵌入式 (Embedded)
嵌入式 (Embedded)
嵌入式部署允许用户将经过训练的 AI 模型集成到嵌入式系统中。由于嵌入式部署的复杂性,需要升级到 嵌入式研发层级 (Embedded R&D Tier) 订阅。用户必须联系 Reality AI 寻求帮助,因为成功的部署通常需要与 Reality AI 团队合作。
嵌入式部署建议
在进行嵌入式部署之前,请考虑以下最佳实践以优化性能并确保兼容性:
| 建议 | 说明 |
|---|---|
| 降低采样率和窗口大小 | 降低这些值可以在保持准确性的同时最大限度地减少内存和处理要求。 |
| 选择复杂度较低的结果 | 在 AI 探索 (AI Explore) 中,优先选择复杂度低的模型。如果复杂度图标为红色,则该模型可能需要 PC 或服务器级硬件。 |
| 使用来自相同硬件的训练数据 | 确保用于训练的数据与部署中使用的硬件和软件相匹配。如有必要,重新收集并重新训练模型。 |
| 部署前测试分类器 | 在将分类器部署到嵌入式系统之前,使用 测试 > 尝试新数据 (Test > Try new data) 和 云 API (cloud API) 在受控环境中验证分类器。这有助于将部署相关问题与模型相关问题隔离开来。 |
嵌入式部分
嵌入式 部分包含两个选项卡:
- 创建包 (Create Package) – 用于从已训练模型生成可部署的包。
- 合并包 (Combine Packages) – 允许合并多个包。
创建包
在 创建包 选项卡中,已训练工具 (Trained Tool) 部分显示可用的已训练模型及其详细信息:
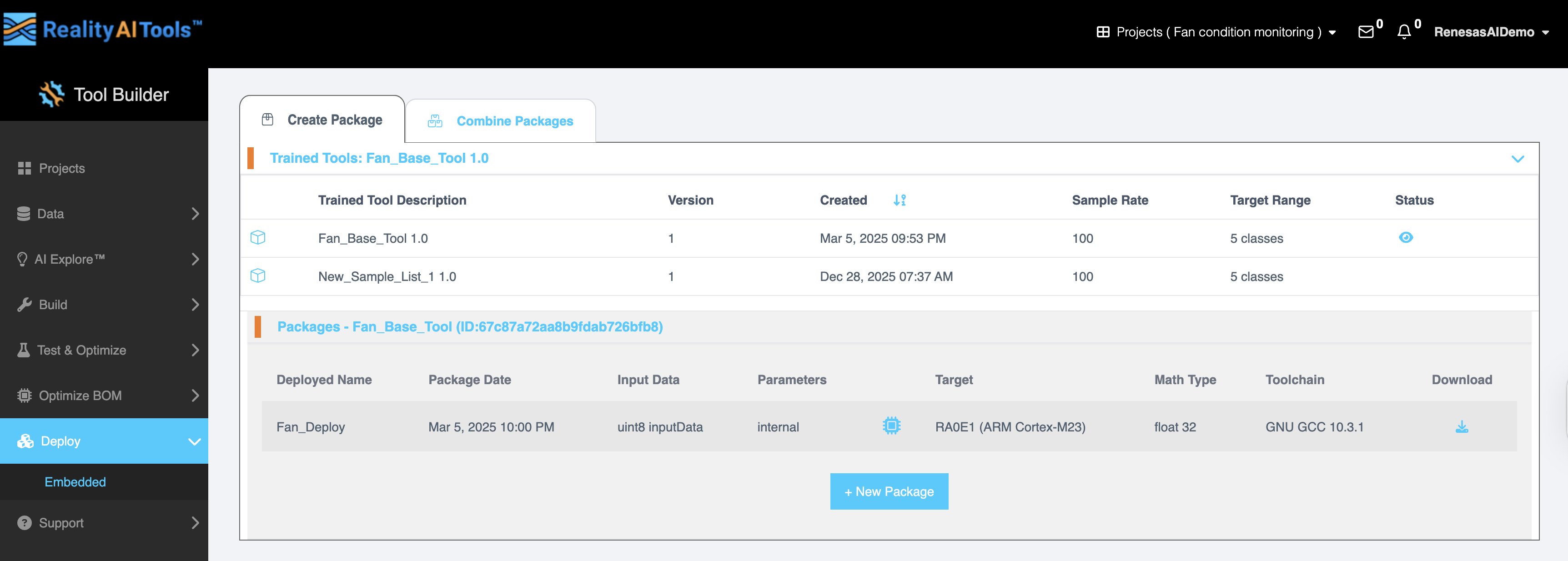
| 字段 | 描述 |
|---|---|
| 已训练工具描述 (Trained Tool Description) | 已训练模型的名称。 |
| 版本 (Version) | 模型的版本号。 |
| 创建时间 (Created) | 创建模型的日期和时间。 |
| 采样率 (Sample Rate) | 数据采样的频率(例如,100 Hz)。 |
| 目标范围 (Target Range) | 分类类别的数量。 |
| 状态 (Status) | 指示模型的当前状态。 |
部署新包
点击 新包 (New Package) 打开 部署新包 (Deploy New Package) 页面,您可以在其中配置部署设置。
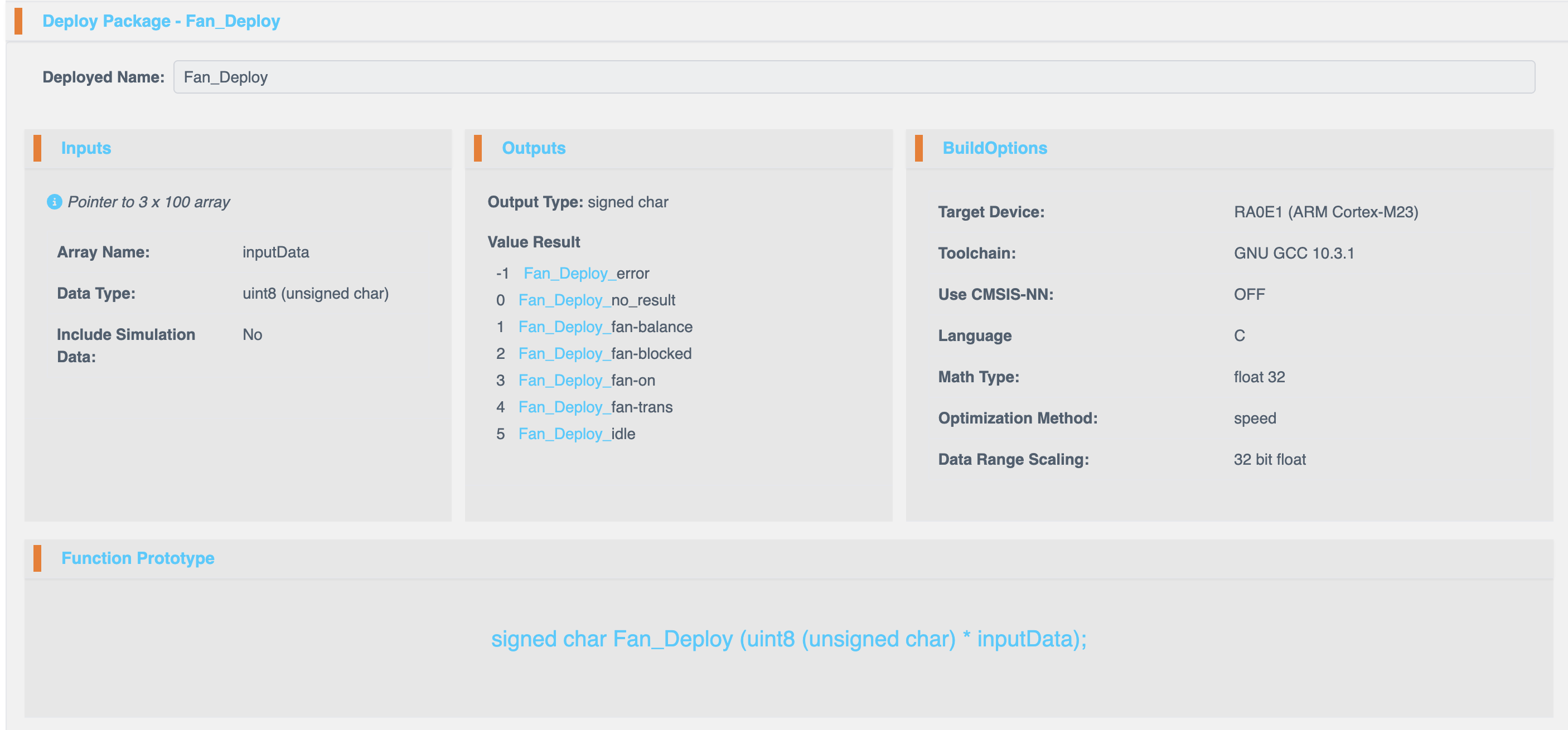
部署配置
部署名称 (Deployed Name)
为新包分配一个自定义名称。
输入配置 (Input Configuration)
| 字段 | 描述 |
|---|---|
| 数组名称 (Array Name) | 输入数组的名称。 |
| 数据类型 (Data Type) | 选择用于输入处理的数据类型。可用选项:- uint8 (无符号字符) - int8 (有符号字符) - uint16 (无符号短整型) - int16 (短整型) - uint32 (无符号整型) - int32 (整型) - float32 (浮点型) - float64 (双精度浮点型) |
输出配置 (Output Configuration)
| 输出类型 | 可能的结果 |
|---|---|
| Signed Char (有符号字符) | -1: _error (错误), 0: _no_result (无结果), 1: _fan_balance (风扇平衡), 2: _fan_blocked (风扇受阻), 3: _fan_on (风扇开启), 4: _fan_trans (风扇过渡), 5: _idle (空闲) |
构建选项 (Build Options)
| 选项 | 描述 |
|---|---|
| 目标设备 (Target Device) | 选择用于部署的硬件平台。 |
| 工具链 (Toolchain) | 选择编译器工具链(例如,GNU GCC 10.3.1)。 |
| 使用 CMSIS-NN | 启用或禁用 CMSIS-NN 以进行神经网络加速。 |
| 数学类型 (Math Type) | 在定点 (Fixed Point) 和浮点 (Floating Point) 运算之间进行选择。 |
| 优化方法 (Optimization Method) | 选择优化 速度 (Speed)(性能)或 大小 (Size)(内存效率)。 |
| 数据范围缩放 (Data Range Scaling) | 默认使用 32 位浮点表示。 |
C 函数原型 (C Function Prototype)
系统提供了一个 C 函数原型,用于将部署的模型集成到外部应用程序中。
示例:
signed char SampleFandata (float32 *inputData);
查看和下载包
创建包后,它将出现在 包 (Packages) 部分,其中包含以下详细信息:
| 字段 | 描述 |
|---|---|
| 部署名称 (Deployed Name) | 已部署包的名称。 |
| 包日期 (Package Date) | 创建包的日期和时间。 |
| 输入数据 (Input Data) | 输入数据的格式和结构。 |
| 参数 (Parameters) | 包中使用的特定设置。 |
| 目标 (Target) | 选定的目标硬件。 |
| 数学类型 (Math Type) | 定点或浮点。 |
| 工具链 (Toolchain) | 使用的编译器工具链。 |
| 下载 (Download) | 将包作为 ZIP 文件下载的选项。 |
查看硬件资源使用情况
点击目标旁边的 微控制器图标 以查看:
| 指标 | 描述 |
|---|---|
| RAM 使用量 (RAM Usage) | 预分配的内存和堆栈使用量。 |
| 存储 (FLASH/ROM) | 参数和代码大小的细分(以字节为单位)。 |
| 推理输出验证 (Inference Output Validation) | 以百分比显示分类准确率。 |
通过遵循这些步骤,您可以成功配置 AI 模型并将其部署到嵌入式环境中,从而确保最佳性能和准确性。如需更多帮助,请联系 Reality AI 支持团队 (Reality AI Support)。