常见问题
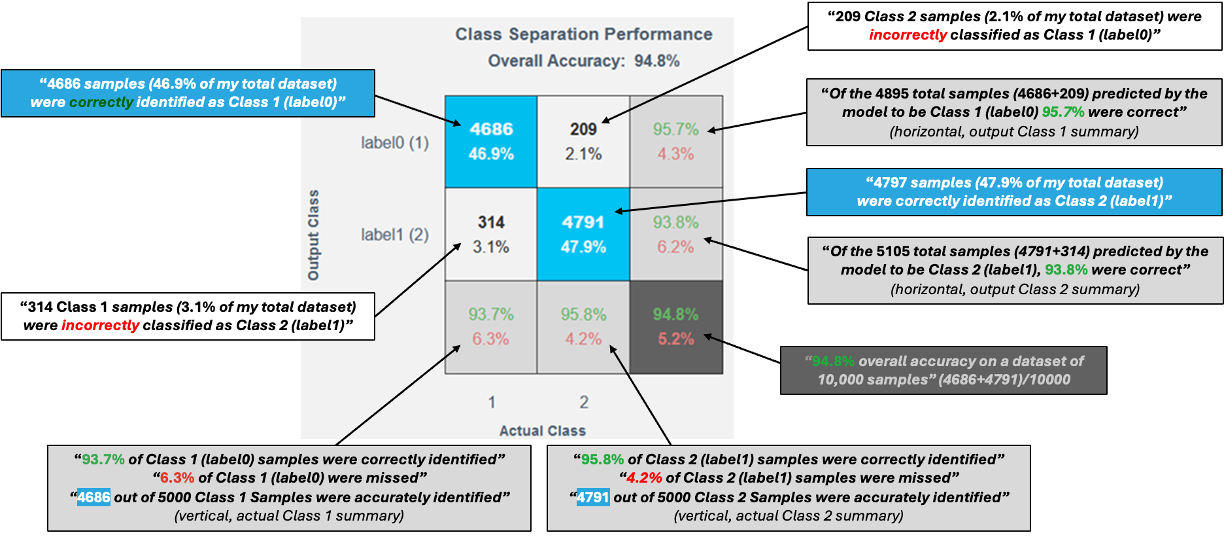
如何读取混淆矩阵?
混淆矩阵 用于评估已训练分类器的性能表现。
矩阵布局
- 行 → 预测类别(模型预测的类别)
- 列 → 实际类别(数据中的真实标签)
关键元素
- 对角线单元格(蓝色)
正确预测- 真正例(True Positive) – 正确预测为正类
- 真负例(True Negative) – 正确预测为负类
- 非对角线单元格(白色)
错误预测- 假正例(False Positive) 和 假负例(False Negative)
- 在多类别模型中,这些单元格显示类别之间的混淆情况
边际信息
- 底部行 → 每个类别的 准确率(绿色) 和 错误率(红色)
- 右下角 → 整体 模型准确率 和 错误率
坐标轴标签映射
- X 轴上的数字直接对应 Y 轴上的类别标签
示例:如果 Y 轴上显示 fan-balance (1),则 X 轴上的 1 也表示同一类别。
数据表示
- 每个数值都对应直方图中的相应数据段。
什么是良好的混淆矩阵?
良好的 混淆矩阵 通常表现为:
- 非对角线(白色)单元格 中的数值非常小
- 对角线 上的数值明显占主导,表示预测正确率较高
NOTE
混淆矩阵不仅显示准确率,还能显示模型在哪些位置出错,因此是改进模型的重要工具。
应如何解释复杂度数值?
复杂度数值表示模型在 MCU / MPU 上部署时的 资源使用情况。
- 这些数值 不是最终值
- 模型通常可以 进一步优化
示例 如果决策重要性图显示最重要的频率带 低于 50 Hz:
- 应用滤波器,仅使用
< 50 Hz的频率 - 减少特征计算
- 节省乘法运算和内存
NOTE
如果在项目创建时已选择目标处理器,则顶部模型已满足该处理器的资源限制。
什么是 One-vs-One 分类策略?
One-vs-One 是一种常用于 多类别分类 的策略。
工作原理
- 为 每一对类别 训练一个二分类器
- 对于
N个类别 → 需要N(N−1)/2个分类器
示例 对于类别 A、B、C,模型将训练:
- A 对 B
- A 对 C
- B 对 C
预测阶段
- 所有分类器并行运行
- 使用 投票或聚合机制 选择最终类别
优势
- 简化复杂的多类别问题
- 通常可提高准确率和可解释性
神经网络模型压缩是如何工作的?
神经网络模型通常比实际需要的更大、更复杂。在使用真实数据进行训练之前,很难确定模型所需的确切规模或架构。
模型压缩通过识别网络中冗余或使用率较低的权重并将其移除来解决这一问题。借助我们专有的数学方法,我们检测这些冗余并重新构建网络,使其更简单、更小且更快。
在整个过程中,我们会在压缩程度与准确率之间进行权衡,以确保不会丢失重要信息。