エラーバランスの調整
このセクションでは、Reality AI Toolsでエラーバランスを調整する方法について包括的なガイドを提供します。**学習済みツール(Trained Tools)およびデータサンプルリスト(Data Sample Lists)**セクションの詳細情報と、提供される機能の使用手順が含まれています。
**エラーバランスの調整(Adjust Error Balance)**機能を使用すると、データサンプルリストと混同行列(Confusion Matrix)の結果に基づいてエラートレードオフを最適化し、学習済みツールのパフォーマンスを分析および微調整できます。
学習済みツール (Trained Tools)
学習済みツールセクションには、主要な属性を持つ学習済みツールの詳細リストが表示されます。このセクションを使用して、分析する特定の学習済みツールを選択します。以下の表は、このセクションで利用可能な詳細の概要です:
| フィールド | 説明 |
|---|---|
| Trained Tool Name | 学習済みツールの名前。 |
| Description | ツールとその目的の簡単な説明。 |
| Version | 学習済みツールのバージョン番号。 |
| Created Date & Time | ツールが作成された日時。 |
| Sample Rate | 学習中に使用されたサンプリングレート(例:Hzまたは1秒あたりのサンプル数)。 |
| Target Range | 分類または予測のターゲット変数の範囲。 |
| Status | ツールの現在のステータス(例:Active(アクティブ)、Inactive(非アクティブ)、Deprecated(非推奨))。 |
データサンプルリスト (Data Sample Lists)
データサンプルリストセクションには、分析に使用されるデータサンプルが含まれています。以下の表は、利用可能な属性の説明です:
| フィールド | 説明 |
|---|---|
| Lock Icon | リストがロックされている(読み取り専用)か、編集可能かを示します。 |
| List Name | データサンプルリストの名前。 |
| List Type | リストのタイプ(例:Training Data(トレーニングデータ)、Test Data(テストデータ)、Validation Data(検証データ))。 |
| Data Shape | データの次元構造(例:行 × 列)。 |
| Sample Rate | データのサンプリングレート。 |
| N Samples | リスト内のサンプルの総数。 |
| Target Range | リストに含まれるターゲット変数の範囲。 |
| Created Date | リストが作成された日付。 |
| Modified Date | リストが最後に更新された日付。 |
| Comments | データサンプルリストに関連付けられたコメントまたはメモ。 |
| Status | リストの現在のステータス(例:Active(アクティブ)、Archived(アーカイブ済み)、Draft(ドラフト))。 |
フィルターアイコンを使用して、以下の基準に基づいて表示されるデータサンプルリストを絞り込みます:
- Name: データリスト名でフィルタリングします。
- List Type: タイプ(例:Training、Testing)でフィルタリングします。
- Date Created: 作成日でフィルタリングします。
- Data Shape: 次元数でフィルタリングします。
- Sample Rate: サンプリングレートでフィルタリングします。
Applyをクリックして選択したフィルターを適用するか、Clearをクリックしてすべてのフィルター値をリセットします。
予測の分析 (Analyze Predictions)
- 学習済みツールとデータサンプルリストの選択: それぞれのセクションから分析用のツールとリストを選択します。
- 分析の開始: **Analyze Predictions(予測の分析)**をクリックして分析プロセスを開始します。ツールはデータを処理し、予測を計算します。
- 分析の停止: 必要に応じて、**Stop Analysis(分析の停止)**をクリックしてプロセスを終了します。
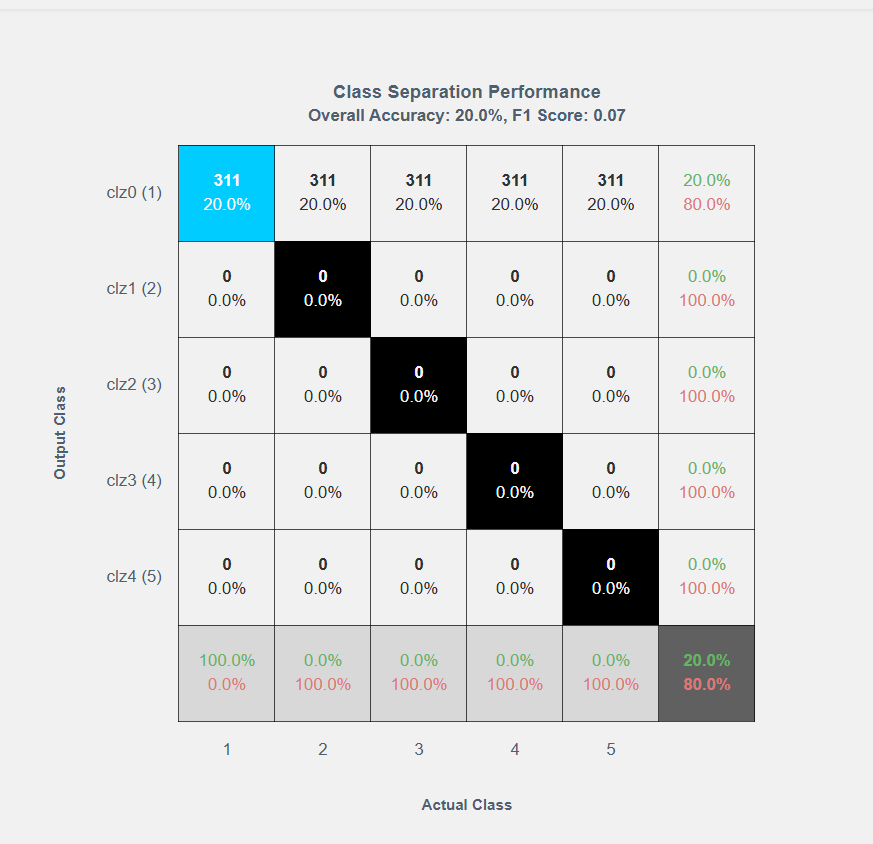
混同行列 (Confusion Matrix)
分析が完了すると、クラス分離パフォーマンス(Class Separation Performance)、全体的な精度(Overall Accuracy)、およびF1スコアを示す**混同行列**が表示されます。混同行列は以下のように構成されています:
- X軸: 実際のクラスを表します。
- Y軸: 予測された(出力)クラスを表します。
混同行列の特徴
- 対角線外のセル: 分類のエラーを強調表示します。特定のエラーを減らすには、対角線外のセルを選択します。
- トレードオフ: 1つのセルを調整すると、他のセルの数値が自動的に調整され、トレードオフが反映されます。
- ROC曲面の最適化: 各調整により、分類器に適した受信者動作特性(ROC)曲面に沿って最適化されたトレードオフが計算されます。
エラーバランスの調整 (Adjusting Error Balance)
行列の右側には、**エラー調整(Error Adjustment)**用のスライダーがあります。エラーバランスを調整するには、以下の手順に従います:
- エラーセルの選択:
- 減らしたい混同行列内の対角線外のエラーセルをクリックします。
- スライダーの使用:
- スライダーを左右に動かして、選択したセルのエラー数を調整します。
- トレードオフを反映して他のセルの数値がどのように変化するかを観察します。
- 変更の保存:
- 調整に満足したら、**Save Changes(変更を保存)**をクリックして最適化されたエラーバランスを適用します。
- ダイアログボックスが表示され、以下の詳細を入力するように求められます:
- New Tool Name: 更新されたツールの名前を入力します。
- Overwrite Existing Tool: 現在のツールを上書きする場合は、このチェックボックスを選択します。
- Save Changesをクリックして確認し、更新を適用します。
- 調整は、分類器のパフォーマンス指標に基づいて動的に計算されます。
- 適合率(Precision)と再現率(Recall)のバランスの取れたトレードオフを維持するために、エラー調整は慎重に使用してください。
- 保存された調整は、将来の分析に反映されます。
これにより、エラーバランスの調整機能を効果的に活用して学習済みツールを微調整し、パフォーマンス結果を向上させることができます。