クラス (Classes)
**Classes(クラス)**セクションでは、以下の3つのタブを通じて新しい分類器を作成および管理できます:
- Data Sample List(データサンプルリスト)
- Distributions for List(リストの分布)
- Exploration Results for List(リストの探索結果)
データサンプルリストタブ (Data Sample List Tab)
このタブには、データサンプルリストのプロパティを表示する詳細な表があります。
| 列 | 説明 |
|---|---|
| Lock Status | リストが編集用にロックされているかどうかを示します。 |
| List Name | データサンプルリストの名前。 |
| List Type | リストのタイプ(例:回帰、分類)。 |
| Data Shape | データの形状(例:行、列)。 |
| N Samples | リスト内のサンプル数。 |
| Target Range | ターゲット値の範囲。 |
| Created | リストが作成された日時。 |
| Modified | リストが最後に変更された日時。 |
| Comments | 追加のメモや観察事項。 |
| Status | リストの現在のステータス(例:アクティブ、アーカイブ済み)。 |
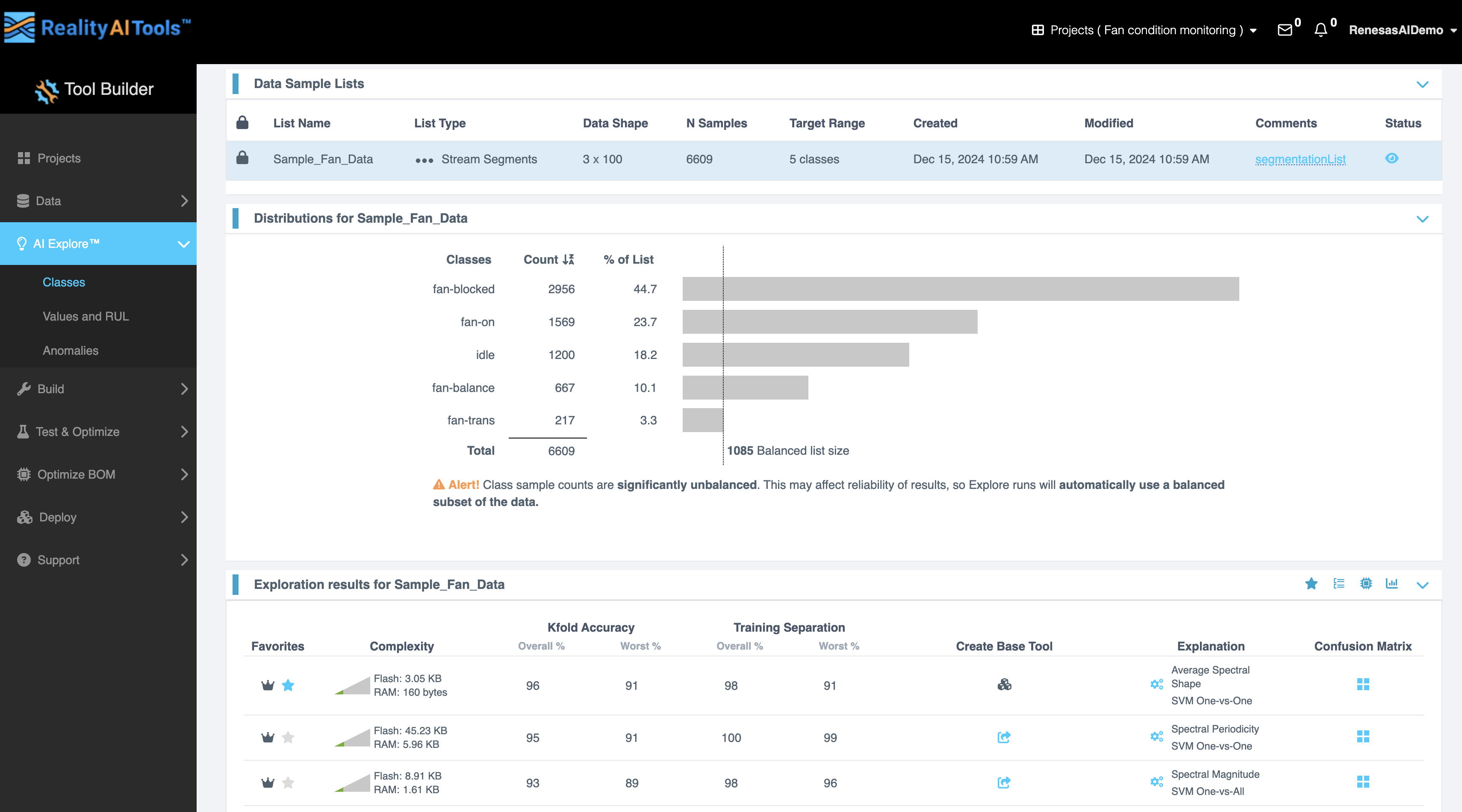
リストの分布タブ (Distributions for List Tab)
このタブには、選択したリスト内のクラスの分布が表示されます。
- 表の列:
- Classes: データ内のクラス名。
- Count: 各クラスのサンプル数。
- % of List: リスト全体における各クラスの割合。
- 特徴:
- 分布のグラフ表現がデータの横に表示されます。
- 総カウント数とバランスの取れたリストサイズも表示されます。
- アラート: クラスのサンプル数が著しく不均衡な場合、アラートが表示されます:
“Class sample counts are significantly unbalanced. This may affect the reliability of results, so Explore runs will automatically use a balanced subset of the data.”(クラスのサンプル数が著しく不均衡です。これは結果の信頼性に影響を与える可能性があるため、Exploreの実行ではデータのバランスの取れたサブセットが自動的に使用されます。)
リストの探索結果タブ (Exploration Results for List Tab)
Start Exploring(探索開始) ボタンをクリックします。
探索結果インターフェース (Exploration Results Interface)
探索を実行すると、提供されたツールやオプションを使用して結果を監視および操作できます。探索結果セクションの各行は、AI Explore の実行中に特定されたさまざまな特徴量に基づく異なるモデルを表しています。このセクションでは、各機能、その目的、および使用手順について概説します。
バックグラウンドで起こっていること
Run Explore ボタンをクリックすると、Reality AIアルゴリズムがデータの分析を開始します。アルゴリズムは、分類問題に合わせて調整された複数の最適化された特徴セットと機械学習モデルを生成します。そして、トップパフォーマンスの結果のみを表示します。
アルゴリズムの仕組み
- バランスの取れたサブセットの作成 アルゴリズムはサンプルリストのバランスの取れたサブセットを作成し、各クラスが同数のサンプルを持つようにします。サンプルリストが非常に大きい場合、処理時間を短縮するためにデータをサブサンプリングすることもあります。
- 特徴量とモデルの最適化 アルゴリズムは、データ内のトレーニングクラスを区別するために最も効果的な特徴セットと機械学習パラメータを特定します。このプロセス中に、何百もの潜在的な特徴セットとモデルを評価します。
- モデルのトレーニングと検証 有望な特徴セットを使用して機械学習モデルを構築し、バランスの取れたサブサンプルでトレーニングします。これらのモデルは、パフォーマンスを評価するために K分割交差検証 (K-Fold Cross-Validation) プロセスを経ます。
- 結果の選択 最もパフォーマンスの良いモデルと特徴セットのみが表示され、最も効果的なソリューションが提供されます。
K分割検証 (K-Fold Validation) とは?
K分割検証は、データセットを K 個の等しい部分(フォールド)に分割してモデルのパフォーマンスを評価する方法です。各フォールドは一度テストセットとして使用され、残りのフォールドはトレーニングに使用されます。
例えば、10分割交差検証 (K=10) の場合:
- データセットは10個のフォールドに分割されます。
- 最初のイテレーションでは、フォールド1がテストに使用され、残りの9個のフォールドがトレーニングに使用されます。
- 2回目のイテレーションでは、フォールド2がテストに使用され、残りはトレーニングに使用されます。
- このプロセスは、10個のフォールドすべてが一度テストセットとして使用されるまで続きます。
Reality AI Toolsは、堅牢で信頼性の高いモデル評価を保証するために、AI Explore ページでの交差検証に K=10 を使用します。
探索中の主なアクション
| アクション | 説明 | 目的と効果 |
|---|---|---|
| Stop Explore | このボタンをクリックすると、探索プロセスが終了します。 | 調整が必要な場合やテストに時間がかかりすぎている場合に役立つ、探索の停止機能です。 |
| Run Explore | クリックすると、Start Explore ボタンが消え、探索が開始されます。 | 探索プロセスを開始します。 |
| Star Icon | 探索の実行後、+ アイコン に置き換わります。 | クリックすると、スター付きの結果が表示されます。 |
| Group by Icon | 特徴空間 (Feature Space) と決定構造 (Decision Structure) のオプションを含むドロップダウンを開きます。 | Feature Space: スペクトログラム、スペクトル特徴量、統計データ、サンプルデータ、位相特徴量などの詳細な特徴量ごとに結果をグループ化します。 Decision Structure: 分類器タイプ (SVM, NN, CNN) ごとに結果をグループ化します。これにより、特徴属性または分類器の方法論によるグループ化が可能になり、ユーザーの好みに基づくデータ分析が簡素化されます。 |
| Microcontroller Icon | Filter Exploration Results ポップアップを開きます。 | ターゲットデバイスを選択し、FlashやRAMサイズなどのパラメータを指定できます。 |
| Graph Icon | クリックすると、データのグラフ表示と表形式表示が切り替わります。 | 複雑さに応じて調整されたグラフとしてデータを表示します。もう一度クリックすると、表形式表示に切り替わります。 |
探索結果のフィルタリング
- Microcontroller Icon(マイクロコントローラアイコン) をクリックして、Filter Exploration Results ポップアップを開きます。
- ドロップダウンメニューからターゲットデバイスを選択します。
- FlashとRAMのサイズは自動的に入力されますが、手動で編集することも可能です。
- 以下のオプションを使用します:
- Clear: フィルターの選択をリセットします。
- Apply: 選択したフィルターを結果に適用します。
データの表示
探索データは最初はグラフで表示されますが、表示を調整するオプションがあります。
| アイコン | アクション | 効果 |
|---|---|---|
| Show More Results | 結果テーブルの下部をクリックして、リストを上位3つの結果以上に展開します。 | 追加の探索結果を表示します。 |
| Show Fewer Results | クリックして、展開された結果を上位3つに戻します。 | ビューを簡素化し、主要な結果に焦点を当てます。 |
データテーブルのフィールド
列 | 説明 |
|---|---|
Favorites | スターアイコンをクリックして、結果をお気に入りとしてマークします。 |
Complexity (Flash/RAM) | このフィールドには、各結果のFlashとRAMの要件が表示され、さまざまな構成のリソース需要を評価できます。
この情報は、リソースに制約のある環境へのモデルの適合性を評価するのに役立ちます。 |
Overall% and Worst% | k-fold交差検証とトレーニング分離の正解率(パーセンテージ)を表示します。 |
Create Base Tool | さらなる処理のために Base Tool(ベースツール) を作成できます。ベースツール は、特定のサンプルリストに含まれるデータから学習できるプログラムです。ベースツール は、データ構造定義、解析/セグメンテーション方法、特徴量選択、機械学習モデル、および出力クラス定義を組み合わせたものです。 |
Explanation | このフィールドは、インタラクティブなプロットを通じて、決定構造、決定の重要性、およびクラスの重要性に関する洞察を提供します。
これらの視覚化は、モデルの動作と予測におけるさまざまな特徴量の重要性を解釈するのに役立ちます。 |
Confusion Matrix | 実際のクラスと出力クラスにわたるk-foldおよびトレーニング分離の結果の詳細ビューを開き、詳細な精度とF1スコア統計を提供します。 |
機能の詳細説明
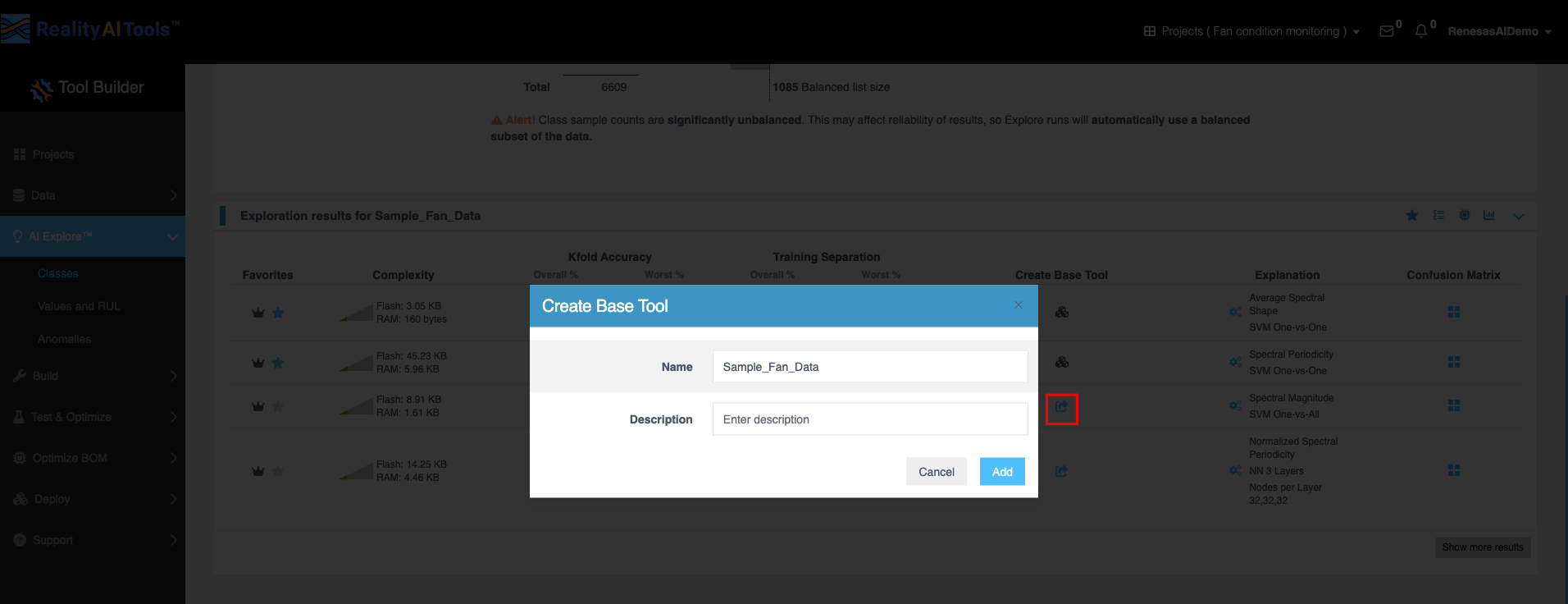
- Create Base Tool:
- Create Base Tool 列のアイコンをクリックしてウィンドウを開きます。
- ツールの名前と説明を入力します。
- Add をクリックしてツールを保存します。
- これが完了すると、アイコンが変わります。
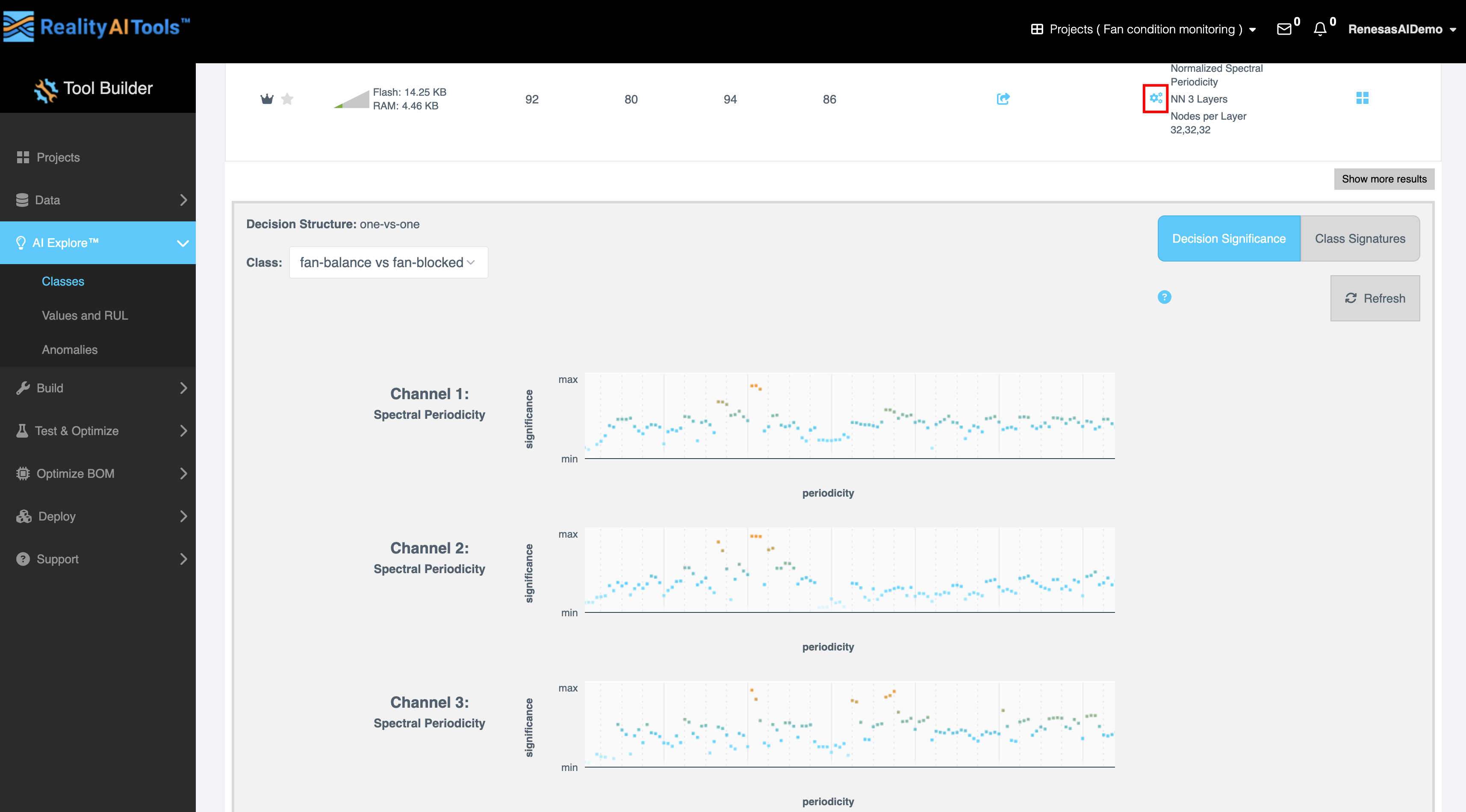
- Explanation(説明):
- 歯車アイコンを選択して以下を表示します:
- Decision Structure: 意思決定パス(one-vs-one)の視覚的表現。One-vs-one(1対1)は、機械学習モデル、特に多クラス分類タスクで使用される分類戦略を指します。
- Class: グラフを生成したい必要なクラスを選択します。
- Decision Significance: オレンジ色(高い重要性)と青色(低い重要性)のブロックを使用して特徴量の影響を表示します。高いオレンジ色のブロックを持つ特徴量は意思決定にとってより重要であり、分類器のパフォーマンスに大きく貢献していることを示します。
- Class Significance: ドロップダウンからクラスを選択して、結果への影響を分析します。
- 歯車アイコンを選択して以下を表示します:
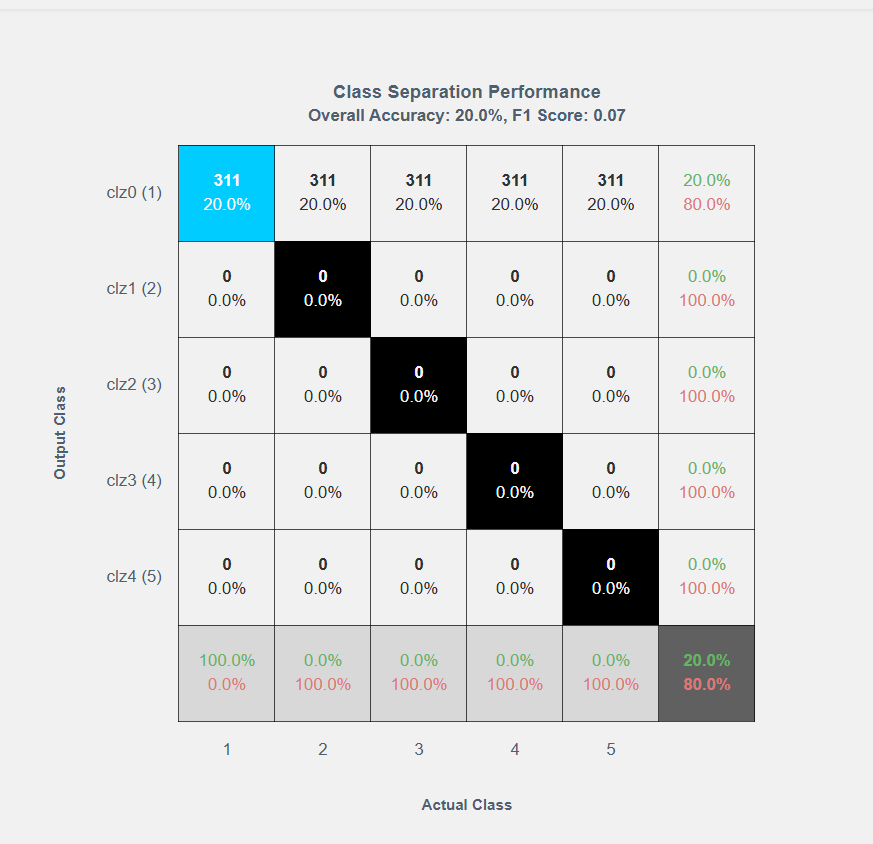
- Confusion Matrix(混同行列):
- Confusion Matrix 列のアイコンをクリックして行列を開きます。
- 実際のクラスと出力クラスにわたるk-foldおよびトレーニング分離データを確認します。
- 3つの行列バリエーションのいずれかを選択します。
- 最初のオプションは、全体的な精度とF1スコアを含む空白の混同行列を表示します。
- 2番目のオプションは、各クラス/カテゴリの精度を表示します。
- 3番目のオプションは、エラー率(パーセンテージ)、混同、および詳細な適合率(Precision)と再現率(Recall)の数値を表示します。
- Clipboard Icon(クリップボードアイコン) をクリックして、外部で使用するために行列データをコピーします。