値とRUL (Values and RUL)
**Values and RUL(値とRUL)**セクションでは、回帰データを効果的に処理できます。RUL は Remaining Useful Life(残存有効寿命) の略で、システムやコンポーネントがメンテナンスや交換を必要とするまでどのくらい機能するかを推定するための、予測モデリングにおける重要な指標です。このセクションは3つのセグメントに分かれています:
- Data Sample List(データサンプルリスト)
- Distributions for [List Name]([リスト名] の分布)
- Exploration Results for [List Name]([リスト名] の探索結果)
各セグメントは、モデル開発のために回帰データを分析および改良するのに役立つ独自の機能と洞察を提供します。
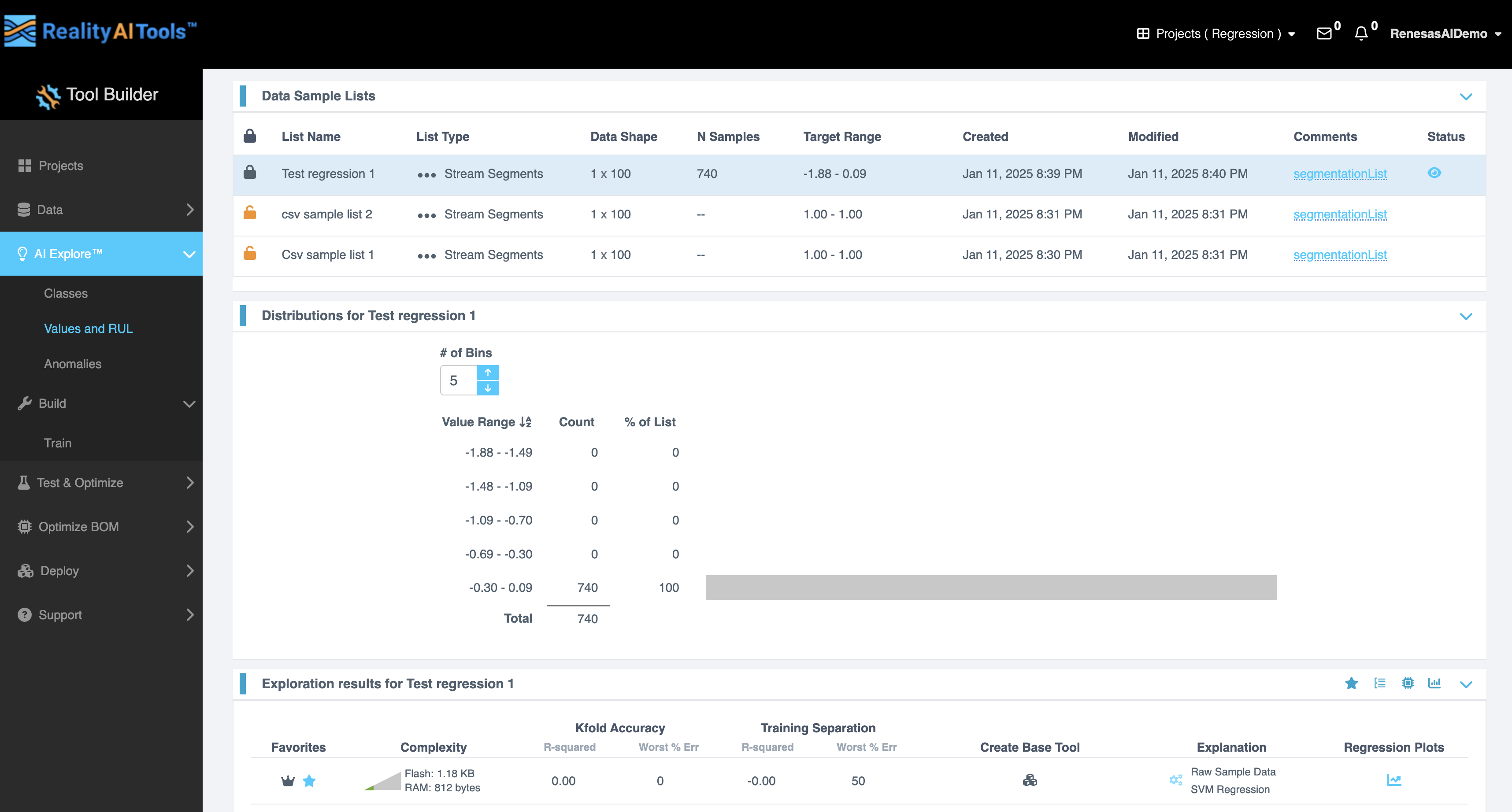
データサンプルリスト (Data Sample List)
Data Sample List セグメントには、以下のフィールドを持つインタラクティブな表が表示されます:
| フィールド | 説明 |
|---|---|
| Lock Symbol | 誤った編集を防ぐために、特定のデータサンプルをロックまたはロック解除できます。 |
| List Name | 現在のデータサンプルリストの名前を表示します。 |
| List Type | リストがトレーニング、検証、またはテストのいずれを目的としているかを指定します。 |
| Data Shape | 特徴量とサンプル数の観点からデータの次元を示します。 |
| N Samples | データリスト内のサンプル数を表示します。 |
| Target Range | データ内のターゲット値の範囲を表示します。 |
| Created | データリストが作成された日時を表示します。 |
| Modified | データリストに対して最後に行われた変更の日時を表示します。 |
| Comments | データリストに関連するメモや備考が含まれます。 |
| Status | データリストの現在の状態(準備完了、進行中、ロック中など)を示します。 |
この表は、回帰データを効率的に整理、レビュー、管理するのに役立ちます。
分布 (Distributions)
Distributions セグメントは、データサンプルの分布を可視化し、データセットの特性に関する重要な洞察を提供します。以下が含まれます:
| フィールド | 説明 |
|---|---|
| # of Bins | ヒストグラムのビン(区間)数を指定します。値を手動で入力するか、上下の矢印を使用して調整できます。 |
| Value Range | 選択したビンの値の範囲を表示します。 |
| Count | 各ビン内のサンプル数を示します。 |
| % of List | 各ビンに含まれるサンプルが全体に占める割合を表示します。 |
| Total Count | データリスト内のサンプルの総数を表示します。 |
このセグメントにより、データ分布のパターンを分析し、異常や不均衡を特定できます。
探索結果 (Exploration Results)
Exploration Results セグメントは、回帰データを評価するための詳細なメトリクスと視覚化を提供します。主な機能は以下の通りです:
| フィールド | 説明 |
|---|---|
| Favorites | お気に入りの構成や結果をマークして、素早くアクセスできるようにします。 |
| Complexity | さまざまな構成におけるFlashやRAMなどのリソース要件を含む、計算の複雑さを表示します。 |
| Kfold Accuracy | 決定係数 (R-squared) や 最悪誤差率 (Worst% Error) の値を含む、交差検証の精度メトリクスを表示します。 |
| Training Separation | 決定係数 (R-squared) や 最悪誤差率 (Worst% Error) の値を含む、トレーニングデータのパフォーマンスメトリクスを提供します。 |
| Create Base Tool | さらなる分析のために、ベースラインツールまたはモデル構成を作成できます。 |
| Explanation | パラメータの決定構造と重要性に関する洞察を提供し、より深い分析のためのインタラクティブなプロットも備えています。 |
| Regression Plots | 散布図や折れ線グラフなどの視覚化を表示し、回帰出力とターゲット値との整合性を表現します。 |
このセグメントは、展開前にモデルを改良し、そのパフォーマンスを理解するために不可欠です。
AIモデルの作成と統計の表示
この手順では、アップロードされたデータセットを使用してAIモデルを作成し、それらのモデルのさまざまな統計を確認する方法を説明します。
- 左側のメニューで、AI Explore > Values and RUL に移動します。
- Data Sample Lists セグメントで、表から必要なセグメント化リストを選択します。
- Exploration Results タブで、Start Exploring(探索開始) をクリックします。
- システムは特徴空間の処理とモデルの生成を開始します。
- 進行状況を監視し、ページにリストされるトップパフォーマンスのモデルを確認できます。
- この段階の詳細については、探索結果インターフェースのセクションを参照してください。
- Exploration Results セクションの各行は、AI探索プロセス中に特定された特徴量に基づくモデルを表します。詳細な精度統計を表示するには、目的のモデルの Regression Plots(回帰プロット) 行をクリックします。
- 空白の Regression Plot が開きます。画面下部で:
- 最初のオプションをクリックして、全体的な精度、F1スコア、エラー分布を含む混同行列 (confusion matrix)を表示します。
- エラー分布プロットを使用して、数値範囲全体でのエラーの集中箇所を特定します。分布が広いほど、モデルのパフォーマンスが低いことを示します。
- 2番目のオプションをクリックして、2つのプロットにアクセスします:
- Regression Plot(回帰プロット): 選択したモデルの実測値と予測値を表示します。
- Residual Error Plot(残差プロット): サンプルごとの残差を表示します。
- 最初のオプションをクリックして、全体的な精度、F1スコア、エラー分布を含む混同行列 (confusion matrix)を表示します。
注意
主要な指標は以下の通りです:
- Residual Error (残差): データポイントと回帰直線の垂直方向の差。予測値と観測値の間の誤差を表します。
- R-squared (R² / 決定係数): 独立変数が従属変数の変動をどれだけ説明できるかの尺度。値が高いほど、適合度が良いことを示します。
- Mean Absolute Error (MAE / 平均絶対誤差): すべての絶対誤差の平均。誤差の平均的な大きさを表します。
- Complexity(複雑さ) タブにカーソルを合わせると、モデルのリソース消費量が表示されます:
- Feature Space: 特徴量計算のための乗算演算。
- Classifier: 分類器に必要な乗算演算(回帰モデルの場合は空白)。
- Total: 全体の乗算演算数。
- ターゲットプロセッサ(MCU/MPU)のモデルリソース要件を測定するために、複雑さの数値を使用します。例えば:
- スペクトルベースの特徴量が重要であり、決定重要度プロット(decision significance plot)で50 Hz未満の周波数が強調されている場合、特徴量計算中に50 Hz未満の周波数用フィルターを適用することで、リソース消費を削減できます。
- プロジェクト作成時にターゲットプロセッサを事前に選択した場合、トップパフォーマンスのモデルは、そのプロセッサの使用可能なリソースに合わせて調整されます。
- 統計を確認した後、強調表示されたオプションをクリックして、さらなるテストまたはエクスポートのためにモデルを展開します。