Curate
- Version 5.6.6
- Version 6.0
Introduction
Curate(整理) ページは、ほとんどの前処理作業が行われる場所です。ここでは、すべてのソースファイルが一貫したサイズの個別のサンプルに解析されます。その後、すべてのサンプルがサンプルリストに追加されます。このセクションには2つのサブタブが含まれています:Source Files と Data Sample Lists。
- Source Files(ソースファイル): プロジェクト中に収集された生データを管理する場所です。
- Data Sample Lists(データサンプルリスト): 利用可能なソースファイルから、より小さくキュレーションされたデータセットを作成します。
長期間データを収集する場合、結果として得られるファイルは、メモリと処理能力が限られているマイクロコントローラユニットにとっては大きすぎることがよくあります。これらのデバイスは、より小さく焦点の絞られたデータセットを処理するように設計されており、意味のあるイベントが発生する重要なインスタンスのみを処理できます。
Curate ページは、大きなデータファイルを小さく管理しやすい断片に分割することでこれを達成するのに役立ちます。このプロセスにより、モデルは実世界のシナリオを模倣するように効果的にトレーニングされ、制約のある環境での展開に向けてパフォーマンスが最適化されます。データファイルを分割することは、これらのブロックがMLモデルへの入力となるため重要です。例えば、データファイルが10秒の場合、それぞれ1秒の10個のセグメントに分割できます。ユースケースの事前知識に基づいてこれらのセグメントの長さを選択するか、1秒のウィンドウ長から始めてそこから実験することができます。
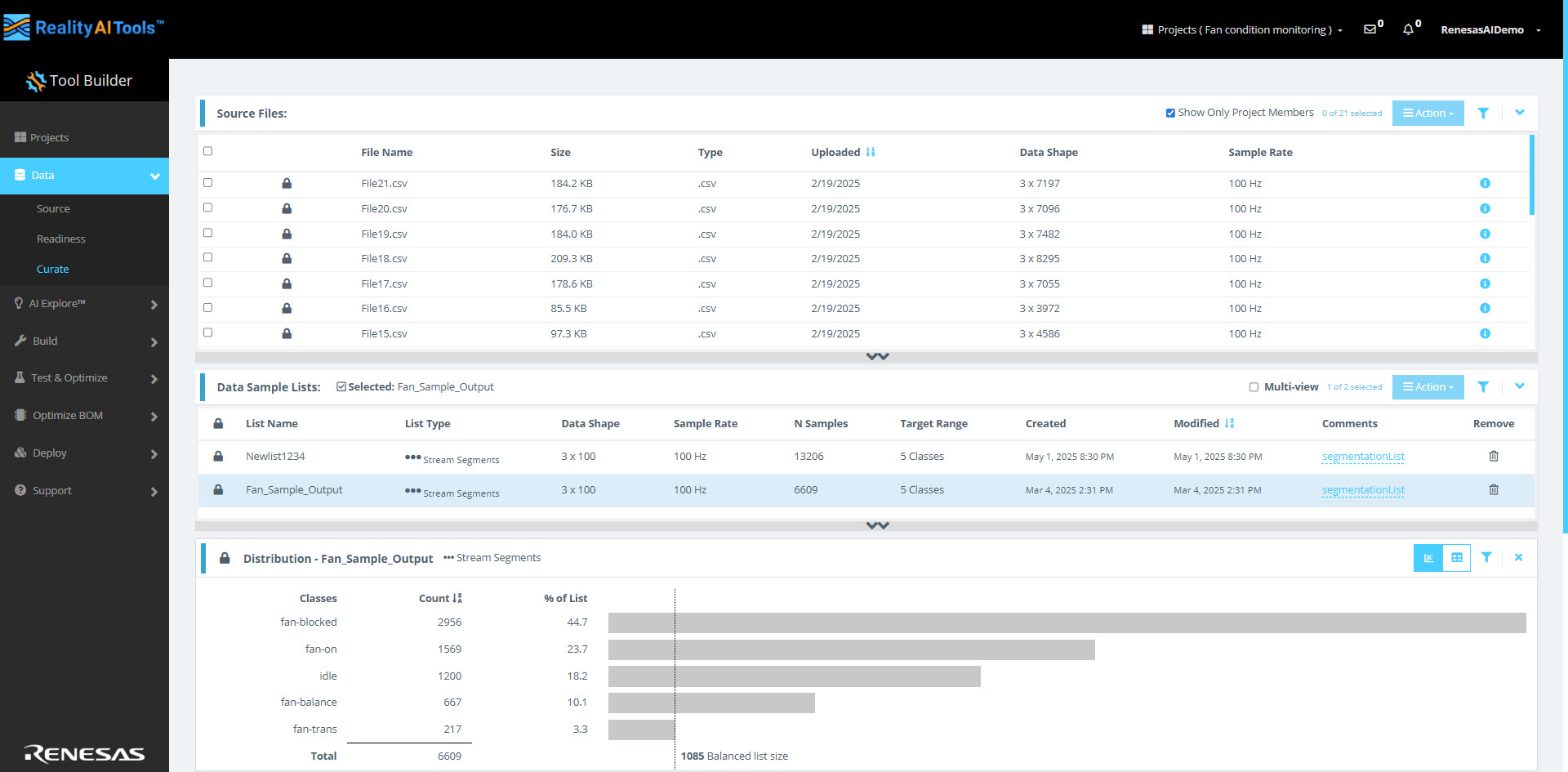
Source Files
ここでは、アップロードされたすべてのデータファイルを、File Name、Size、Type、Uploaded date、Data Shape、Sample Rate とともに確認できます。
Viewing Project Members
Show Only Project Members チェックボックスを選択して、表示されるソースファイルをフィルタリングし、プロジェクトメンバーに関連付けられたファイルのみを表示するように制限します。
Actions
Action ドロップダウンメニューには、以下のオプションがあります:
- Select All: リストされたすべてのファイルを選択します。
- Deselect All: すべてのファイルの選択を解除します。
- New List From Selected: 選択したファイルを使用して新しいリストを作成します。
- Segment List From Selected: 選択したファイルからセグメント化リストを作成します。
- Edit Metadata Type: 選択したファイルのメタデータタイプを変更します。
- Format Selected: 選択したファイルのファイル形式を定義または更新します。
- Remove Selected: 選択したファイルをプロジェクトから削除します。
- Import Metadata: メタデータファイルをアップロードして、ソースファイルのメタデータを追加または更新します。
- Close: 変更を行わずにアクションメニューを終了します。
Creating a Segmented List
ファイルにラベルを付けた後、セグメント化リストを作成して、分析とトレーニングのためにデータをより小さく管理しやすいサンプルに分割できます。セグメンテーション方法とオプションを効果的に構成するには、以下の手順に従ってください。
なぜセグメンテーションが必要なのか?
セグメンテーションは、マイクロコントローラ(MCU)を使用するものなど、リソースに制約のある環境での展開に最適化されたモデルを生成する上で重要な役割を果たします。これらのモデルは、ライブデータを迅速かつ効率的に処理するように設計されており、多くの場合、1秒、500ミリ秒、またはさらに短い期間などの小さな時間枠内で処理します。
実際のアプリケーションでは、モデルは長く途切れない記録ではなく、短く連続的なデータストリームに基づいて予測を行う必要があります。トレーニング段階でこのシナリオを再現するために、生データはより小さなセグメントに分割されます。これらのセグメントはモデルのトレーニングに使用され、ライブの本番環境で遭遇するデータのタイプを学習し、適応できるようになります。
このアプローチにより、限られた処理能力とメモリの制約内で動作しながら、リアルタイムシナリオでモデルが効果的に機能することが保証されます。
セグメント化リストを作成する手順
- Actions > Segment List from Selected に移動します。
- Segment Files ウィンドウが開き、セグメンテーション用に選択されたファイルが表示されます。
- Segmentation Method ドロップダウンメニューから、以下の方法のいずれかを選択します:
- Sliding CSV Window
- Energy Triggered
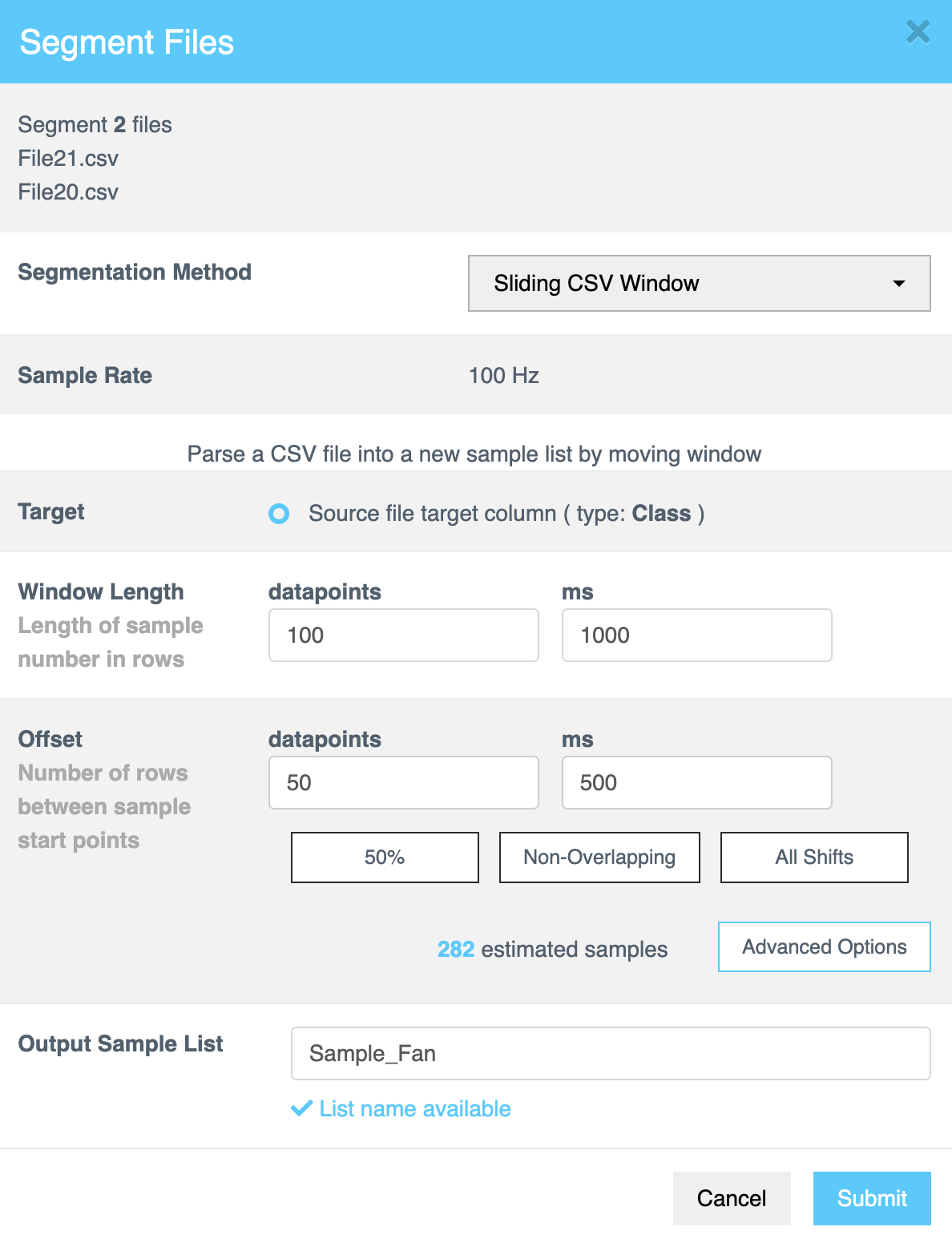
Sliding CSV Window(スライディングCSVウィンドウ)の設定
Sliding CSV Window 方式は、ファイル全体を通してステップバイステップのスライディングウィンドウアプローチを使用して、CSVデータ [数値、テキストベース、または時系列データ] をより小さく管理しやすいサンプルに分割し、ファイル全体が処理されるまで各ステップでデータをキャプチャします。以下の表は、この方法で利用可能な設定オプションをまとめたものです:
オプション | 説明 |
|---|---|
Sample Rate | CSVファイルをサンプルリストに解析するための固定サンプリングレートを表示します。この値はファイルフォーマット中に固定されます。 |
Target | ファイルメタデータからターゲット列を選択します(タイプ:Class)。 |
Window Length | Window Length は、セグメンテーションに使用される決定ウィンドウのサイズを決定します。各サンプルの長さを行数またはミリ秒 (ms) で指定します。この値は、AIが各セグメントを分類するためにどれだけのデータを分析するかを制御します。 ヒント: データセットに最適な構成を特定するために、さまざまなウィンドウ長で実験してください。 |
Offset | Offset は、ソースファイル内の連続するサンプルの開始点間のギャップを指定します。パーサーが新しいサンプルウィンドウを作成する前にどれだけ移動するかを定義するために、行数またはミリ秒 (ms) で値を入力します。 |
50% Overlap |
|
Non-Overlapping |
|
All Shifts |
|
Advanced Options(詳細オプション)
Advanced Options をクリックして、セグメンテーションをさらにカスタマイズします。
| オプション | 説明 |
|---|---|
| Restart Streamed Window | 各クラスまたはメタデータブロックの開始時にウィンドウを再起動します。 |
| Respect Transitions: クラスまたはメタデータブロック内の遷移が処理されるようにします。 | |
| Class: クラスブロック内の遷移を特に処理します。 | |
| Keep Short Window Samples | ファイルまたはクラスブロックの終わりにある短いサンプルの処理方法を決定します。 |
| Retain Short Samples: 出力に短いサンプルを含めます。 | |
| 1 per Block: ブロックごとに1つの短いサンプルを保持します。 | |
| Output Type | セグメント化されたサンプルの保存方法を選択します: |
| Output to New List: セグメント化されたサンプルの新しいリストを作成します。 | |
| Append to Existing List: 既存のリストに解析されたサンプルを追加します。 |
Explorer Tier(エクスプローラー層)には、作成できるセグメント化リストを7,000サンプル未満に制限する制限があります。
Output Sample List
セグメンテーションを設定した後、Output Sample List ページでセグメント化されたサンプルリストの名前を指定します。このフィールドは必須です。
| アクション | 説明 |
|---|---|
| Submit | 構成を確認し、プロセスを完了します。 |
Submitをクリックした後、約30秒待ってからページを更新してください。ページを更新した後、Data Sample List タブをクリックします。タブをクリックすると、処理が完了したリストが表示されるはずです。
このデータセットのセグメント化/分割には1分もかかりません。ただし、セグメンテーションの所要時間はデータセットのサイズに依存します。例えば:1 GBのファイルはセグメント化に5〜10分かかる場合があります。
Energy triggered(エネルギートリガー)
エネルギートリガーオプションを選択すると、必要に応じて以下の設定を構成できます。このセグメンテーション方法は、音声ベースの信号などの回帰データセットに特に適しています。
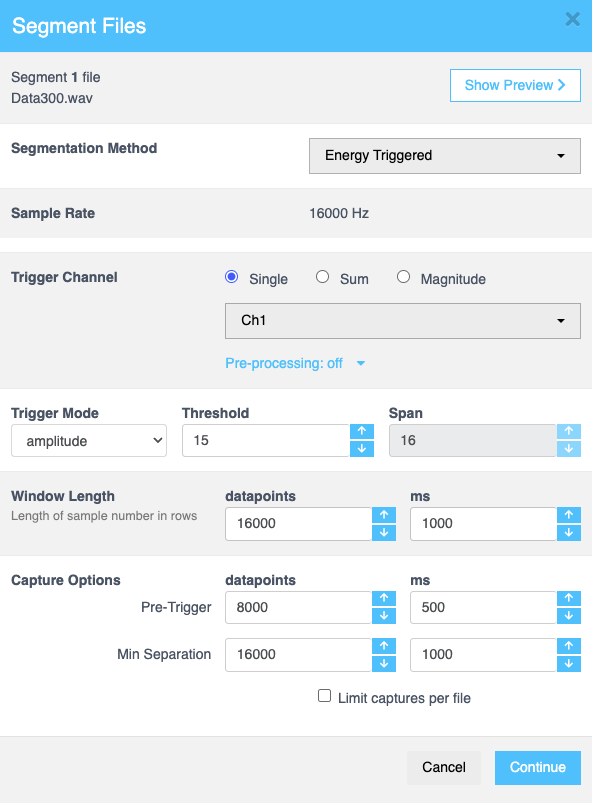
| フィールド | 説明 |
|---|---|
| Show/Hide Preview | ファイル名、選択されたクラス、トリガーポイント、キャプチャウィンドウ、およびデータのグラフ表現を含む、データファイルの概要を表示します。この機能により、プレビューの更新、データの開始点と終了点の設定、グラフ表現内でのパンとズーム、包括的な分析のためのファイル全体の表示が可能になります。 |
| Sample Rate | データがサンプリングされる頻度を設定します。エネルギートリガーイベントの場合、正確なデータキャプチャを保証するために自動的に100 Hzに設定されます。手動入力は不要です。これはファイルフォーマット中に固定されます。 |
| Trigger Channel | トリガー検出のソースを決定します。オプションは以下の通りです: |
| - Single: ドロップダウンメニューから特定のチャンネルを選択して、エネルギートリガーイベントを監視します | |
| - Sum: チャンネルを数学的に結合(例:合計または差分)して、複数のチャンネルにまたがるトリガー条件を定義できます。 | |
| - Magnitude: 結合された大きさを計算することで、複数のチャンネルを同時に監視できます。 | |
| Pre-Processing | データの正規化を設定します。このオプションを有効にするには Normalize チェックボックスを選択します。これによりデータがスケーリングされ、均一性が確保され、サンプル間の比較が改善されます。 |
| Zeroing | データ処理のゼロ化方法を調整します。オプションは以下の通りです: |
| - None: ゼロ化調整を適用せず、元のデータを保持します。 | |
| - DeMin: 最小値を減算してデータのベースラインを調整します。 | |
| - DeMean: 平均値を減算してデータを中央揃えにし、分析用にゼロ中心のデータを確保します。 | |
| Zero Window | ゼロ化調整が適用される期間を指定します。選択したウィンドウ全体でのベースラインドリフトを管理するのに役立ちます。必要な値を入力するか、上下の矢印を使用して調整します。 |
| Filter | データ処理のフィルタタイプを設定します。オプションは以下の通りです: |
| - None: データにフィルタは適用されません。 | |
| - Low: ローパスフィルタを適用して高周波ノイズを除去し、分析用に低い周波数を保持します。 | |
| - Band: バンドパスフィルタを適用して指定された範囲内の周波数を分離し、この帯域外の周波数を除去します。 | |
| - High: ハイパスフィルタを適用して低周波ノイズを除去し、分析用に高い周波数を保持します。 | |
| Trigger Mode | トリガーのモードを決定します。オプションは以下の通りです: |
| - Amplitude: データの振幅(信号強度)に基づいてトリガーを検出します。 | |
| - + Crossing: 信号が正のしきい値を超えたときにトリガーします。 | |
| - - Crossing: 信号が負のしきい値を超えたときにトリガーします。 | |
| - RMS: トリガー検出に二乗平均平方根(RMS)値を使用し、信号の全体的なエネルギーに焦点を当てます。 | |
| - RMS Step: RMS値のステップ変化に基づいてトリガーします。 | |
| - RMS Step Ratio: 連続するRMSステップ変化の比率に基づいてトリガーを検出します。 | |
| - Peak to RMS Ratio: ピーク信号値とそのRMS値の比率に基づいてトリガーします。過渡信号の識別に役立ちます。 | |
| - Diff: 連続するデータポイント間の差分に基づいてトリガーを検出します。 | |
| - Sign: トリガー検出のために信号の符号(正または負)を監視します。 | |
| Threshold | イベントをトリガーするために必要な最小信号レベルを指定します。必要な値を入力するか、上下の矢印を使用します。 |
| Span | トリガー検出の期間または範囲を定義します。Trigger Modeで Amplitude、Diff、または Sign が選択されている場合、このフィールドは非アクティブになります。 |
| Window Length | 分析に使用される行のサンプル数を設定します。キャプチャされたデータの解像度を制御するのに役立ちます。値を直接入力するか、上下の矢印を使用して調整します。 |
| Datapoints | 選択したウィンドウ内で分析するデータポイントの数を指定します。必要な値を入力するか、上下の矢印を使用して調整します。 |
| ms | 時間分析のためのウィンドウ長をミリ秒単位で定義します。必要な値を入力するか、上下の矢印を使用して調整します。 |
| Capture Options | データキャプチャのプリトリガーまたは最小分離値を設定します: |
| - Pre-Trigger: トリガーイベントが発生する前にキャプチャされるデータ量を決定し、イベント前の状態を理解するのに役立ちます。 | |
| - Min Separation: 冗長なデータのキャプチャを避けるために、連続するトリガーイベント間の最小間隔を確保します。 | |
| Limit Captures Per File | ファイルサイズを管理し、データの整理を改善するために、単一ファイルに保存されるキャプチャ数を制限します。このオプションを有効にするにはチェックボックスを選択します。 |
Continue をクリックして、以下のように詳細を入力します:
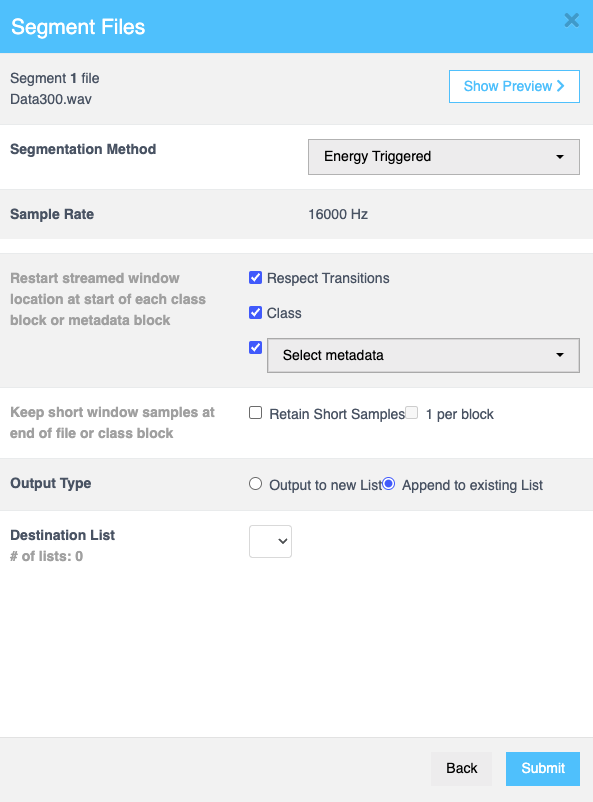
| フィールド | 説明 |
|---|---|
| Restart streamed window location at start of each class block or metadata block | Respect Transitions チェックボックスを選択すると、Class および Metadata チェックボックスが編集可能になります。Metadata を選択するとドロップダウンが表示され、必要なメタデータを指定できます。 |
| Keep short window samples at end of file or class block | Retain Short Samples チェックボックスを選択して、ファイルまたはクラスブロックの終わりにある短いサンプルを保持します。また、1 per block チェックボックスを有効にして、ブロックごとに1つの短いサンプルを保持することもできます。 |
| Output type | Output to new List または Append to existing List のいずれかをラジオボタンを使用して選択し、新しいリストを作成するか、結果を既存のリストに追加するかを決定します。 |
| Output Sample List | このフィールドは Output to new List を選択した場合に使用可能です。処理されたサンプルが保存される出力リストの名前を入力します。 |
| Destination List | このフィールドは Append to existing List を選択した場合に使用可能です。ドロップダウンメニューから必要なリストを選択します。 |
Submit をクリックして確認します。
Filtering Source Files
- Filter アイコンをクリックして、Filter Source Files ページを開きます。
- 利用可能なフィルターを使用して検索を絞り込みます:
- Name: 名前でファイルを検索。
- Data Type: データタイプに基づいてフィルタリング。
- Date: ファイル作成日または変更日でフィルタリング。
- Data Shape: データ形状に基づいてファイルを絞り込み。
- Sample Rate: サンプルレートでフィルタリング。
- Unformatted: フォーマットされていないファイルを検索。
- Assigned Targets: ターゲットが割り当てられたファイルをフィルタリング。
- Unassigned Targets: ターゲットが割り当てられていないファイルを見つける。
- 必要なフィールドに入力した後、Apply をクリックしてソースファイルをフィルタリングします。
Defining the Target Class
データのターゲットクラスを定義するには、2つのオプションがあります:
- ソースファイルの追加列を使用: ソースファイルをアップロードする際、各データポイントのラベルを指定する追加の列を含めます。
- メタデータファイルを使用: 以下の2列を持つ metadata という名前のCSVファイルを準備します:
-
- File Name: アップロードしたすべてのファイル名のリスト。
- Label Type: 各ファイルの対応するラベル。
- File Name: アップロードしたすべてのファイル名のリスト。
-
例えば、「リンゴ」のファイルが10個、「オレンジ」のファイルが5個ある場合、メタデータファイルでそれに応じてラベルを割り当てます。
メタデータのインポート
- Curate ページの Source Files タブで、Action > Import Metadata オプションを使用してメタデータファイルをアップロードします。
- ダイアログボックスが表示され、準備したCSVファイルをドラッグアンドドロップできます。
- 2行目のドロップダウンから Target Value を選択します。1行目のドロップダウンは File Names のままにします。これにより、割り当てられたメタデータに従ってファイルにラベルが付けられます。
- アップロードされると、記述的なメタデータがソースファイルに追加されます。
ターゲットクラスの表示
メタデータをインポートした後、Sample Rate 行の横にある矢印を展開します。Amps 列には、すべてのファイルのターゲットクラス選択が表示されます。
この方法は、各ソースファイルに追加の列を手動で追加するのが面倒な場合、大量のファイルを扱う際に特に有益です。
Data Sample Lists
このセクションでは、Segment List from Selected アクションを実行した後に生成される Output Sample Lists の操作方法について説明します。これらのリストは以下の詳細とともに表形式で表示されます:
| フィールド | 説明 |
|---|---|
| List Name | サンプルリストの名前。 |
| List Type | 分類や回帰など、リストのタイプを指定します。 |
| Data Shape | リスト内のデータの形状または次元。 |
| Sample Rate | サンプルが収集されたレート。 |
| N Samples | リスト内のサンプル数。 |
| Target Range | リスト内のターゲット値の範囲。 |
| Created | リストが作成された日時。 |
| Modified | リストが最後に更新された日時。 |
| Comments | データサンプルリストに関するコメントまたはメモを追加できます。 |
| Remove | 表から特定のサンプルリストを削除できます。 |
Multi-view Option
ツールバーで Multi-view チェックボックスを選択すると、リストをより効果的に比較および分析するために、複数のビューで表示できます。
Actions
Actions ドロップダウンメニューを使用してサンプルリストを管理します。以下のアクションが利用可能です:
| アクション | 説明 |
|---|---|
| Deselect All | 選択されたすべての項目の選択を解除します。 |
| Random Subset to New | 選択された項目のランダムなサブセットから新しいリストを作成します。 |
| Edit Sensor Groups | 選択されたリストのセンサーグループを調整します。 |
| Convert to Regression List/ Convert to Classification List | 選択された分類リストを回帰リストに変換するか、その逆を行います。 |
| Remap Classes | 選択されたリスト内のクラスラベルを再割り当てします。 |
| Export to CSV | 選択されたリストをCSVファイルとして保存します。 |
| Import From CSV | CSVファイルをアップロードしてデータサンプルリストを追加または更新します。 |
| Close | 変更を行わずにアクションメニューを閉じます。 |
| Remove Selected | 選択されたデータサンプルリストを削除します。 |
Filtering Lists
サンプルリストをフィルタリングして特定の項目を見つけることができます。
- Filter アイコンをクリックして Filter Lists ページを開きます。
- 提供されたオプションを使用してリストをフィルタリングします:
- Name: 名前でリストを検索。
- List Type: タイプでリストをフィルタリング。
- Date Created: 作成日に基づいてリストを絞り込み。
- Data Shape: データ形状でリストをフィルタリング。
- Sample Rate: サンプルレートに基づいてリストを検索。
- フィルターフィールドに必要な情報を入力し、Apply をクリックして表示されるリストを絞り込みます。
Distribution
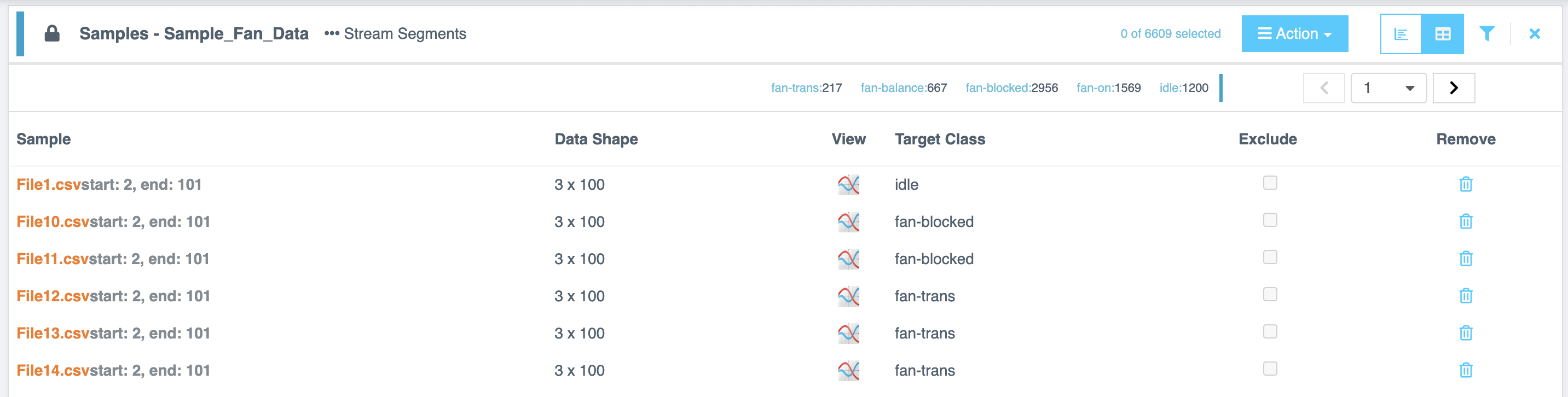
ソースファイルをセグメント化して作成されたサンプルリストは、AI Exploration、Training、または Testing に使用できます。各行には、ソースファイルストリームから取得された、設定された長さの特定のラベル付きサンプルまたは観測データが含まれています。
新しく作成されたセグメント化リストをクリックして、その内容を表示します。このリストには、セグメント化されたデータのブロックまたはウィンドウが表示されます。データのヒストグラムも視覚化のために表示されるはずです。
セグメンテーション直後にヒストグラムが表示されない場合は、ページを更新してみてください。
選択したリストの分布を List View または Table View で分析できます。
表示オプション
| ビュー | 説明 |
|---|---|
| List View | Classes、Count、および % of List ごとに分布の詳細を表示します。 |
| Table View | Sample File, Data Shape, View, Target Class ドロップダウン(クラスの検索または作成)、および Exclude と Remove オプションを含む、各サンプルの詳細情報を提供します。 |
テーブルビューでのアクション実行
- ツールバーの Action ボタンを選択します。
- 以下のオプションから選択します:
| アクション | 説明 |
|---|---|
| Transfer | 選択した項目を別のリストに転送します。 |
| Transfer to New List | 選択した項目から新しいリストを作成します。 |
| Select All | すべての項目を選択します。 |
| Select All on Page | 現在のページに表示されているすべての項目を選択します。 |
| Select Random Subset | 項目のランダムなサブセットを選択します。 |
| Deselect All | すべての選択を解除します。 |
| Set Target for Selected | 選択した項目にターゲットクラスを割り当てます。 |
| Exclude Selected | 選択した項目をリストから除外します。 |
| Include Selected | 以前に除外された項目を含めます。 |
| Export to CSV | 選択した項目をCSVファイルに保存します。 |
| Import CSV | CSVファイルから項目をインポートします。 |
| Close | 変更を行わずにアクションメニューを閉じます。 |
| Remove Selected | 選択した項目を削除します。 |
Introduction
**Curate(整理)**ページは、AI探索(AI Exploration)、トレーニング、またはテストの前に、ほとんどの前処理作業が行われる場所です。このページでは、ソースファイルが一貫したサイズの個別のサンプルに解析され、これらのサンプルがサンプルリストにグループ化されます。
Curate ページには3つのメインタブがあります:
- Project Files(プロジェクトファイル) - アップロードされたファイルの表示、メタデータの管理、データセット用のファイルの準備を行います。
- Data Sets(データセット) - ファイルをデータセットに結合し、セグメンテーション(分割)パラメータを設定し、センサーグループを管理します。
- Sample Lists(サンプルリスト) - モデルのトレーニングと評価のために、キュレーション(整理)されたサンプルのサブセットを生成および管理します。
長期間にわたってデータが収集される場合、メモリと処理能力が限られているマイクロコントローラユニット(MCU)で効率的に作業するには、ファイルが大きすぎることがあります。これらのデバイスは、最も意味のあるイベントのみを捉える、より小さく焦点の絞られたデータセットに最適化されています。
Curate ページは、大きなデータファイルを小さく管理しやすいセグメント(区間)に分割することで、この課題に対処します。これらのセグメントは、MCU上に展開されたモデルの実世界の動作条件をシミュレートします。そこでは、ライブデータの小さなスライディングウィンドウ上で継続的に予測が行われます。
例えば、10秒間のデータファイルは、それぞれ1秒間の10個のセグメントに分割できます。セグメントの長さの選択は、ユースケースによって異なります。ドメイン知識(例えば、200ミリ秒続く振動パターンなど)を使用するか、デフォルトの1秒から始めて、モデルの精度を最適化するために短いウィンドウや長いウィンドウで実験することができます。
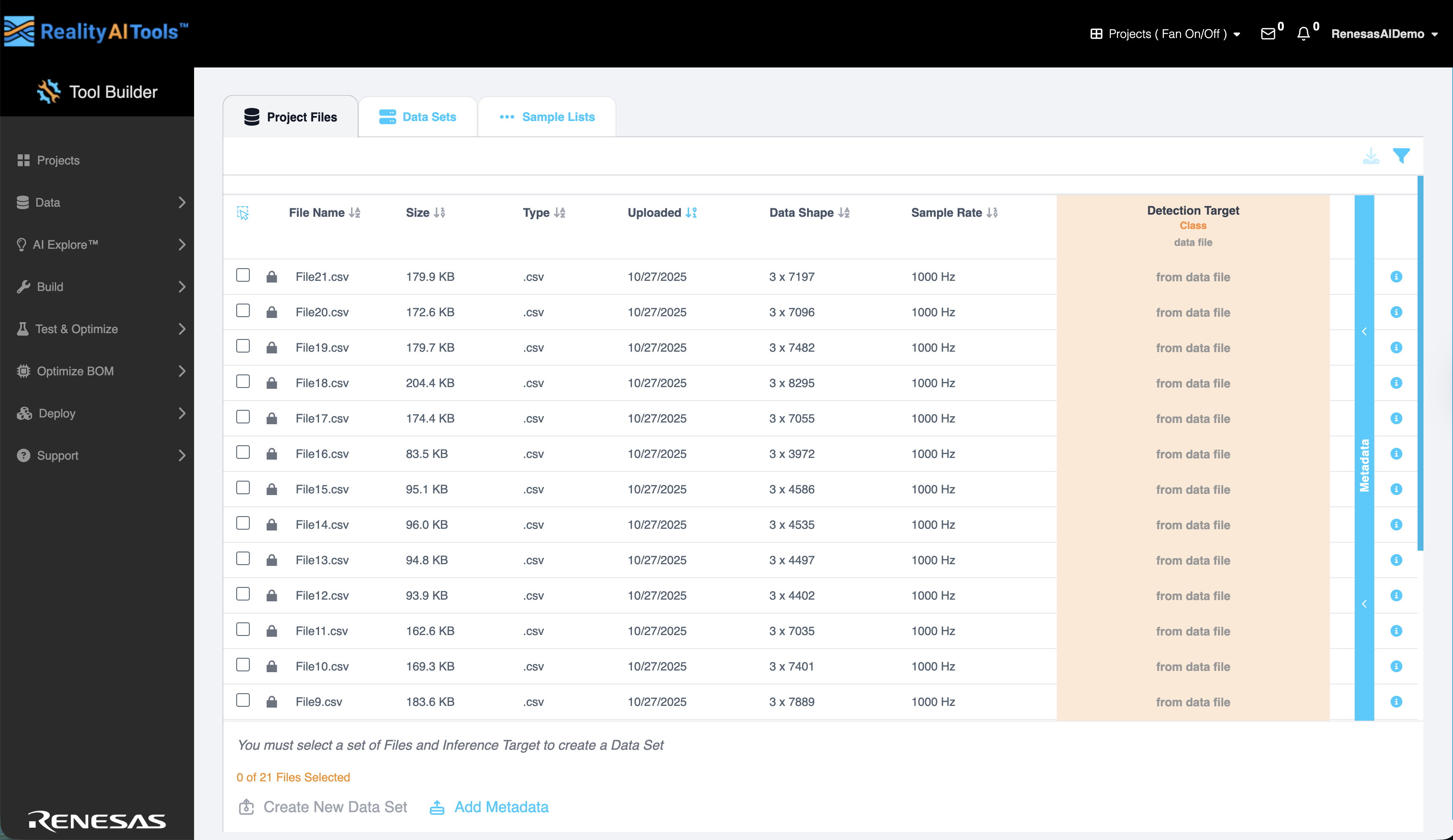
Project Files
Project Files タブには、アップロードされたすべてのデータファイルとそれに関連する詳細が表示されます:
- File Name - アップロードされたファイルの名前。
- Size - ファイルサイズ。
- Type - ファイルタイプ。
- Uploaded - ファイルが追加された日付。
- Data Shape - ファイルの次元構造(行数x列数)。
- Sample Rate - サンプルが収集されたレート。
- Inference Target - 予測されるラベルまたは値。
- Metadata - ファイルにリンクされた追加の記述情報。
Adding Metadata to Project Files
メタデータは、トレーニング中のデータのフィルタリング、ラベル付け、または分割に使用できる追加の記述フィールドを提供します。
- Project Files タブで、Metadata セクションを展開して既存のメタデータを表示します。
- Add Metadata を選択します。Add Metadata ダイアログが開きます。
- .csvファイルをダイアログにドラッグアンドドロップしてアップロードします。このファイルには、ファイルに関連付けたいメタデータ値が含まれている必要があります。
インポートされると、メタデータはプロジェクトファイルにリンクされ、Metadata セクションに表示されます。
Configure Import Settings
Add Metadata ウィンドウで、ファイル形式に合わせてインポートオプションを設定します:
- CSVにヘッダー行が含まれている場合は、Label Row チェックボックスを選択します。選択すると、ヘッダー行はインポートされたデータから除外されます。
- Delimiter ドロップダウンから、ファイルで使用されている列区切り文字を選択します。サポートされている区切り文字には、カンマ (,)、セミコロン (;)、スペース ( )、および タブ (\t) があります。
- ファイルが小数点としてカンマを使用している場合(例:1,234,567.89 ではなく 1.234.567,89)、European Decimals チェックボックスを選択します。
- Confirm を選択してインポートを完了し、Project Files タブにメタデータを表示します。
Selecting Metadata Type
正しいメタデータタイプを割り当てることで、正確なデータ処理とモデルトレーニングが保証されます。メタデータファイルをアップロードした後:
- 設定するメタデータ列を選択します。
- Select Metadata Type ドロップダウンを開きます。
- 列の内容に応じて、以下のタイプのいずれかを選択します:
- Target Class - カテゴリカルな結果ラベル。
- Target Value - 回帰に使用される数値ターゲット。
- Categorical Metadata - 記述的なカテゴリフィールド(例:マシンID)。
- Numerical Metadata - 連続的な数値。
- Sequential #s / Time Code - フレームやタイムスタンプ値などの順序付けられたデータ。
- Date and Time、Date Only、または Time Only - 時間ベースのフィールド。
- Ignore - 処理から列を除外します。
メタデータタイプが割り当てられると、それらは Project Files タブに表示されます。
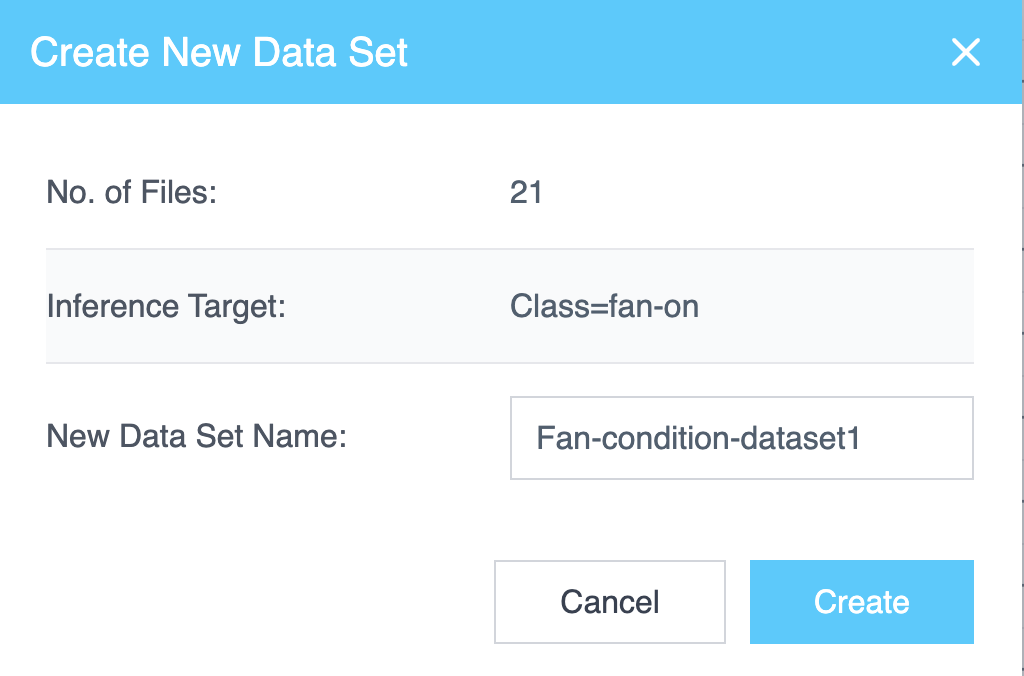
Creating a New Data Set
データセットを作成するには:
- Project Files タブで、含めたい各ファイルの横にあるチェックボックスを選択します。複数のファイルを選択できます。
- Create New Data Set を選択します。
Create New Data Set ダイアログには以下が表示されます:
- Number of Files Selected(選択されたファイル数)
- Inference Target(推論ターゲット)
- New Data Set Name(新しいデータセット名)を入力するフィールド
名前を入力し、Create を選択してデータセットを生成します。
データセットが既に存在する場合、ボタンは Add to Data Set に変わります。これを選択すると、既存のデータセットのリストが開き、Create New Data Set オプションも表示されます。選択したファイルを既存のデータセットに追加するか、新しいデータセットを作成できます。
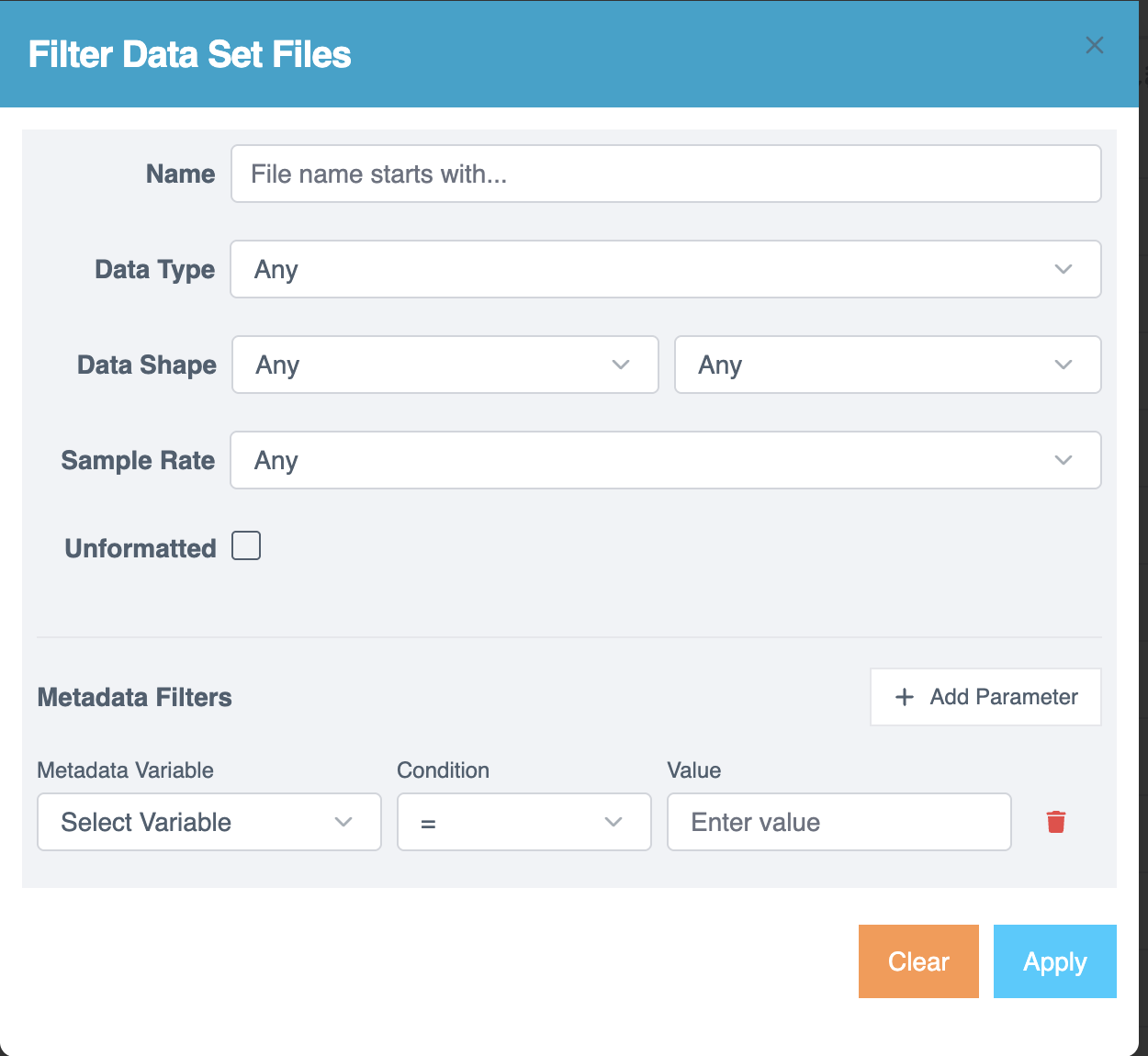
Filtering Project Files
フィルターを使用してファイルを素早く見つけます:
- Filter アイコンを選択して、Filter Data Set Files ページを開きます。
- 必要に応じてフィルターを適用します:
- Name - ファイル名で検索。
- Data Type - データタイプでフィルタリング。
- Data Shape - データ形状で結果を絞り込み。
- Sample Rate - サンプリングレートでフィルタリング。
- Unformatted - まだフォーマットされていないファイルを特定。
- 高度なフィルタリングには Metadata Filters セクションを使用します:
- Metadata Variable - 変数を選択。
- Condition - 演算子を選択
(=, ≠, >, <, ≥, ≤, Contains, Starts with, Ends with, Regex)。 - Value - 比較値を入力。
- + Add Parameter を選択して複数の条件を含めます。
- Trash アイコンを選択して条件を削除します。
- Apply を選択して結果をフィルタリングします。
Data Sets
Data Sets タブには、作成されたすべてのデータセットと以下の詳細が表示されます:
- Name
- Creation Date
- Number of Files
- Data Shape
- Sample Rate
- Total Size
- Inference Target
データセットを選択すると、ファイル名、サイズ、タイプ、アップロード日、データ形状、サンプルレート、推論ターゲット、選択されたメタデータなど、詳細なファイル情報が表示されます。
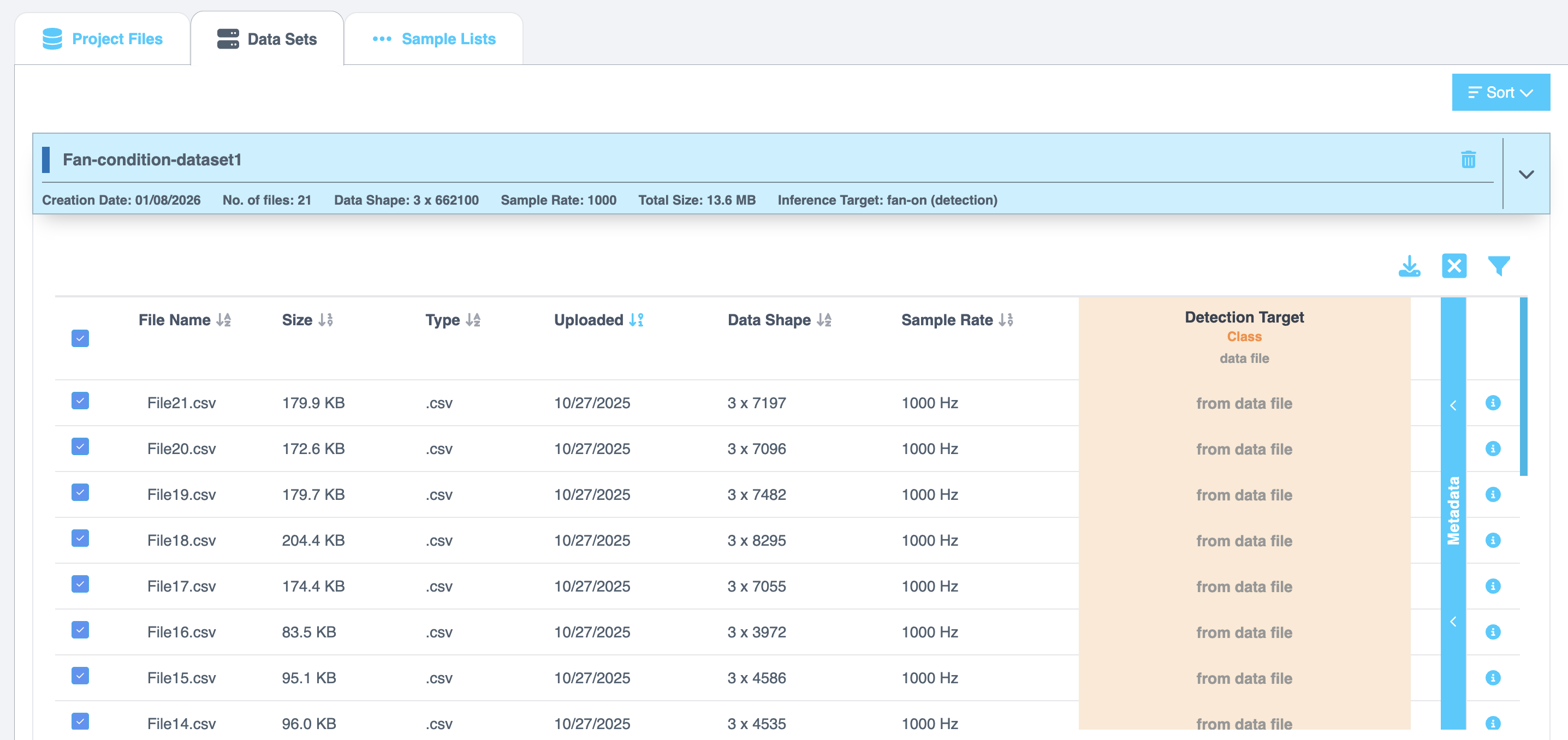
Additional Configuration Options
- Data Channels - データセット内のすべてのチャンネルをリストします。デフォルトでは、すべてのチャンネルが選択されています。チェックボックスを使用してチャンネルを含めるか除外します。
- Manage Sensor Groups を選択して Sensor Groups ダイアログを開き、以下を行うことができます:
- センサーグループの追加、名前変更、または削除。
- グループへのデータチャンネルの割り当て。
- 変更を保存して適用。
- Manage Sensor Groups を選択して Sensor Groups ダイアログを開き、以下を行うことができます:
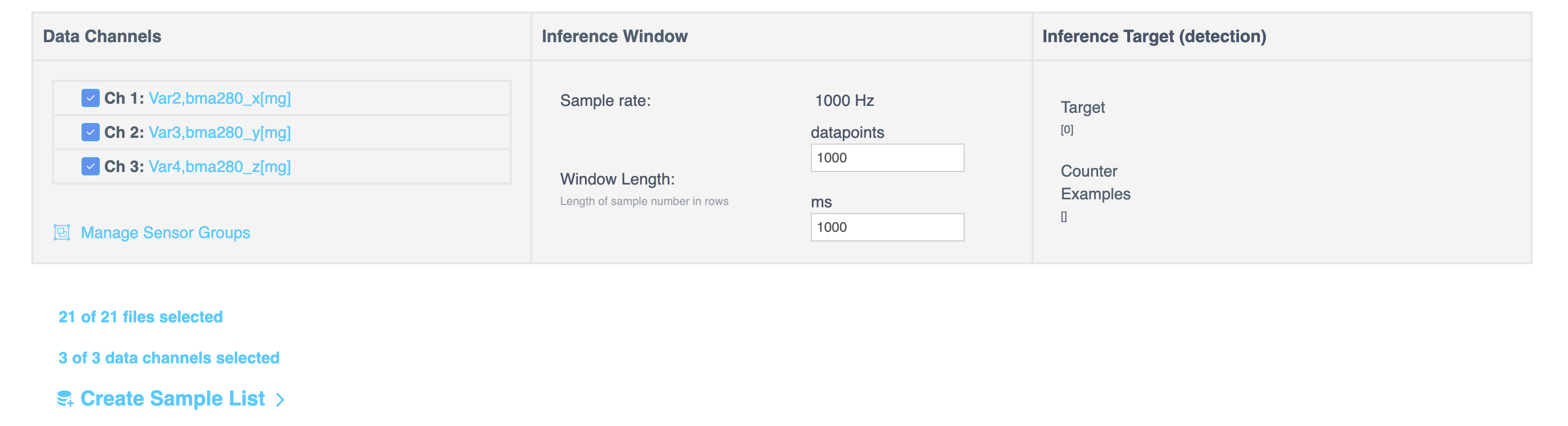
- Inference Window - 以下を表示します:
- Sample Rate (Hz)
- Window Length(データポイントとミリ秒の両方で表示)。これらの値を編集してセグメンテーションを構成できます。
- Inference Target - 推論ターゲット変数の分布を表示します。ヒストグラムはビン(区間)に分割されており、上下の矢印を使用してビンの数を調整できます。カウントと範囲は動的に更新されます。
タブの下部には、サマリーが表示されます:
- 選択されたファイルの総数
- 選択されたチャンネルの総数
続行するには、Create Sample List を選択します。以下から選択してください:
- Single List
- Random Split
- Split by Metadata
Creating a Segmented List
セグメンテーションは、生データをより小さく均一なサンプルに分割するプロセスです。このステップは、制約のあるデバイス上でリアルタイムに動作できるモデルをトレーニングするために重要です。
なぜセグメンテーションが必要なのか?
セグメンテーションは、マイクロコントローラ(MCU)を使用するものなど、リソースに制約のある環境での展開に最適化されたモデルを生成する上で重要な役割を果たします。これらのモデルは、ライブデータを迅速かつ効率的に処理するように設計されており、多くの場合、1秒、500ミリ秒、またはさらに短い期間などの小さな時間枠内で処理します。
実際のアプリケーションでは、モデルは長く途切れない記録ではなく、短く連続的なデータストリームに基づいて予測を行う必要があります。トレーニング段階でこのシナリオを再現するために、生データはより小さなセグメントに分割されます。これらのセグメントはモデルのトレーニングに使用され、ライブの本番環境で遭遇するデータのタイプを学習し、適応できるようになります。
このアプローチにより、限られた処理能力とメモリの制約内で動作しながら、リアルタイムシナリオでモデルが効果的に機能することが保証されます。
Creating a Single List
Single List を選択して、1つのセグメント化リストを作成します。Segment Files to Sample List ダイアログが開きます。セグメンテーション方法、ウィンドウ長、その他のオプションを設定し、リストを生成します。
ランダム分割(Random Split)の作成
Random Split を選択して、トレーニングとテストのためにデータを複数の分割(フォールド)にパーティション分割します。ダイアログには以下が含まれます:
- Folds: 作成するフォールドの数を入力します。フォールドとは、データセットが複数のサブセットに分割されたときに作成されるパーティションの1つです。これらのフォールドは、トレーニングとテストにデータを割り当てるために使用され、データセットの異なる部分でモデルが評価されることを保証します。
- Train: トレーニングに使用するデータの割合を入力します。
- Test: テストに使用するデータの割合を入力します。
Continue をクリックして設定を確認します。その後、Segment files to sample list ダイアログが開きます。
Creating a Split by Metadata
Split by Metadata を選択して、Source File、Target Value、またはユーザー定義のメタデータなどのメタデータフィールドに基づいてデータを分割します。選択されたメタデータフィールドはその分布を表示します。選択後、ダイアログにはメタデータフィールド、その値、および作成されるサンプルリストの数が表示されます。
Continue をクリックして設定を確認します。その後、Segment files to sample list ダイアログが開きます。
Segment Files to Sample List
このダイアログでは、ファイルをサンプルリストにセグメント化する方法を構成します。
| オプション | 説明 |
|---|---|
| File names | セグメント化されるファイルの数と名前 |
| Data Channels | 前のセクションで選択されたデータチャンネルの数とリスト。 |
ダイアログは、選択された Segmentation Method(セグメンテーション方法) に基づいて動的に更新されます。Sliding CSV Window または Energy Triggered を選択できます。
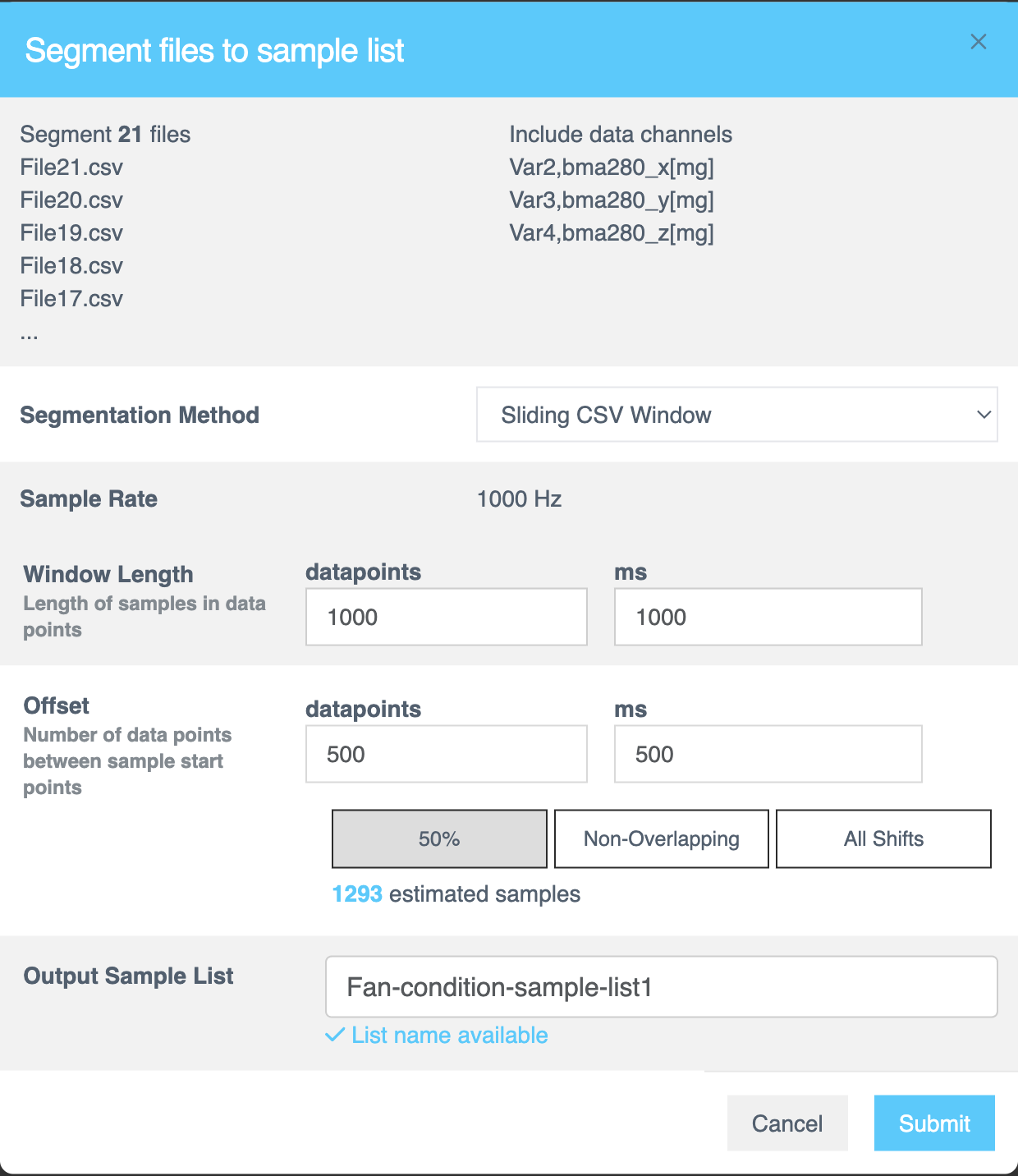
Sliding CSV Windowを選択した場合:
Segmentation method | Sliding CSV Window 方式は、ファイル全体を通してステップバイステップのスライディングウィンドウアプローチを使用して、CSVデータ [数値、テキストベース、または時系列データ] をより小さく管理しやすいサンプルに分割し、ファイル全体が処理されるまで各ステップでデータをキャプチャします。 |
|---|---|
Sample Rate | CSVファイルをサンプルリストに解析するための固定サンプリングレートを表示します。この値はファイルフォーマット中に固定されます。 |
Window Length | Window Length は、セグメンテーションに使用される決定ウィンドウのサイズを決定します。各サンプルの長さを行数またはミリ秒 (ms) で指定します。この値は、AIが各セグメントを分類するためにどれだけのデータを分析するかを制御します。 ヒント: データセットに最適な構成を特定するために、さまざまなウィンドウ長で実験してください。 |
Offset | Offset は、ソースファイル内の連続するサンプルの開始点間のギャップを指定します。パーサーが新しいサンプルウィンドウを作成する前にどれだけ移動するかを定義するために、データポイントまたはミリ秒 (ms) で値を入力します。選択に基づいて推定サンプル数を確認できます。 |
50% Overlap |
|
Non-Overlapping |
|
All Shifts |
|
Output Sample List | セグメンテーションを設定した後、セグメント化されたサンプルリストの名前を指定します。このフィールドは必須です。 |
Energy Triggeredを選択した場合:
Segmentation method | Energy Triggered 方式は、信号内の検出されたエネルギーイベントに基づいてデータをセグメント化し、トリガー条件が満たされた場合にのみサンプルをキャプチャします。このアプローチは、音声信号のような回帰データセットに特に適しており、正確なイベント駆動型データ分析を保証します。 |
|---|---|
Sample Rate | データがサンプリングされる頻度を設定します。エネルギートリガーイベントの場合、正確なデータキャプチャを保証するために自動的に100 Hzに設定されます。手動入力は不要です。これはファイルフォーマット中に固定されます。 |
Window Length | 分析に使用される行のサンプル数を設定します。キャプチャされたデータの解像度を制御するのに役立ちます。値を直接入力するか、上下の矢印を使用して調整します。 |
Trigger Channel | トリガー検出のソースを決定します。オプションは以下の通りです: |
| |
| |
| |
Pre-Processing | データの正規化を設定します。このオプションを有効にするには Normalize チェックボックスを選択します。これによりデータがスケーリングされ、均一性が確保され、サンプル間の比較が改善されます。 |
Zeroing | データ処理のゼロ化方法を調整します。オプションは以下の通りです: |
None: ゼロ化調整を適用せず、元のデータを保持します。 | |
DeMin: 最小値を減算してデータのベースラインを調整します。 | |
DeMean: 平均値を減算してデータを中央揃えにし、分析用にゼロ中心のデータを確保します。 | |
Zero Window | ゼロ化調整が適用される期間を指定します。選択したウィンドウ全体でのベースラインドリフトを管理するのに役立ちます。必要な値を入力するか、上下の矢印を使用して調整します。 |
Filter | データ処理のフィルタタイプを設定します。オプションは以下の通りです: |
- None: データにフィルタは適用されません。 | |
- Low: ローパスフィルタを適用して高周波ノイズを除去し、分析用に低い周波数を保持します。 | |
- Band: バンドパスフィルタを適用して指定された範囲内の周波数を分離し、この帯域外の周波数を除去します。 | |
- High: ハイパスフィルタを適用して低周波ノイズを除去し、分析用に高い周波数を保持します。 | |
Trigger Mode | トリガーのモードを決定します。オプションは以下の通りです: |
- Amplitude: データの振幅(信号強度)に基づいてトリガーを検出します。 | |
- + Crossing: 信号が正のしきい値を超えたときにトリガーします。 | |
- - Crossing: 信号が負のしきい値を超えたときにトリガーします。 | |
- RMS: トリガー検出に二乗平均平方根(RMS)値を使用し、信号の全体的なエネルギーに焦点を当てます。 | |
- RMS Step: RMS値のステップ変化に基づいてトリガーします。 | |
- RMS Step Ratio: 連続するRMSステップ変化の比率に基づいてトリガーを検出します。 | |
- Peak to RMS Ratio: ピーク信号値とそのRMS値の比率に基づいてトリガーします。過渡信号の識別に役立ちます。 | |
- Diff: 連続するデータポイント間の差分に基づいてトリガーを検出します。 | |
- Sign: トリガー検出のために信号の符号(正または負)を監視します。 | |
Threshold | イベントをトリガーするために必要な最小信号レベルを指定します。必要な値を入力するか、上下の矢印を使用します。 |
Span | トリガー検出の期間または範囲を定義します。Trigger Modeで Amplitude、Diff、または Sign が選択されている場合、このフィールドは非アクティブになります。 |
Capture Options | データキャプチャのプリトリガーまたは最小分離値を設定します: |
- Pre-Trigger: トリガーイベントが発生する前にキャプチャされるデータ量を決定し、イベント前の状態を理解するのに役立ちます。 | |
- Min Separation: 冗長なデータのキャプチャを避けるために、連続するトリガーイベント間の最小間隔を確保します。 | |
Limit Captures Per File | ファイルサイズを管理し、データの整理を改善するために、単一ファイルに保存されるキャプチャ数を制限します。このオプションを有効にするにはチェックボックスを選択します。 |
Output Sample List | セグメンテーションを設定した後、セグメント化されたサンプルリストの名前を指定します。このフィールドは必須です。 |
右側のパネルでは、選択したファイルをプレビューできます。オレンジ色の線はトリガーポイントを表し、青い線はキャプチャウィンドウを表します。ズームをサポートする概要とともに複数のチャンネルを表示できます。ズームインするには、概要でセクションを選択してドラッグします。ズームされたビューは上のチャンネル表示に現れます。
ビューを更新するには Refresh Preview を選択します。
注意
Explorer Tier(エクスプローラー層)には、作成できるセグメント化リストを7,000サンプル未満に制限する制限があります。
| アクション | 説明 |
|---|---|
| Submit | 構成を確認し、プロセスを完了します。 |
Submitをクリックした後、約30秒待ってからページを更新してください。ページを更新した後、Data Sample List タブをクリックします。タブをクリックすると、処理が完了したリストが表示されるはずです。
注意
このデータセットのセグメント化/分割には1分もかかりません。ただし、セグメンテーションの所要時間はデータセットのサイズに依存します。例えば:1 GBのファイルはセグメント化に5〜10分かかる場合があります。
Sorting Data Sets
右上の Sort オプションを使用してデータセットを並べ替えることができます。利用可能なオプションは以下の通りです:
- Creation Date (Old - New)
- Creation Date (New - Old)
- Inference Target
- Sample Rate
- Data Shape
Sample Lists
このセクションでは、Segment List from Selected アクションを実行した後に生成される Sample Lists の操作方法について説明します。これらのリストは以下の詳細とともに表形式で表示されます:
| フィールド | 説明 |
|---|---|
| List Name | サンプルリストの名前。 |
| Data Shape | リスト内のデータの形状または次元。 |
| Sample Rate | サンプルが収集されたレート。 |
| N Samples | リスト内のサンプル数。 |
| Target Range | リスト内のターゲット値の範囲。 |
| Modified | リストが最後に更新された日時。 |
| Comments | データサンプルリストに関するコメントまたはメモを追加できます。 |
| Info | Info アイコンを選択すると、名前、推論ウィンドウ、サンプルレート、形状、オフセット、データチャンネル、ファイル名などの詳細が表示されます。 |
| Remove | ゴミ箱 アイコンを選択すると、サンプルリストが削除されます。 |
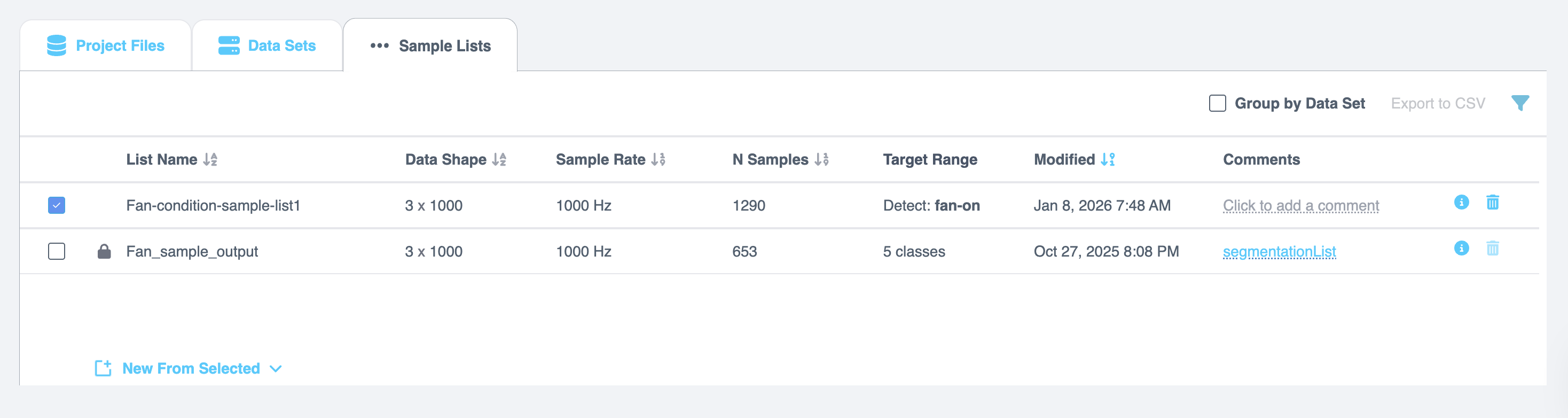
Managing Sample Lists
Group by Data Set(データセットでグループ化)
Group by Data Set チェックボックスを選択して、サンプルリストをデータセットグループごとに整理します。
Create a New List from Selected Rows(選択した行から新しいリストを作成)
- サンプルリストから1つ以上の行を選択します。
- New from selected ドロップダウンメニューを開きます。
- 以下のオプションのいずれかを選択します:
- Copy Sample List - 選択したリストのコピーを作成します。
- Random Subset - 選択したサンプルのランダムなサブセットを含む新しいリストを作成します。
- Concatenate - 選択したリストを単一のリストに結合します。
Copy Sample List(サンプルリストのコピー)
Copy Sample List を選択すると、Copy to New List ウィンドウが開きます。
- List Name フィールドに新しい名前を入力します。
- Create を選択してコピーされたリストを生成します。
Random Subset(ランダムサブセット)
Random Subset を選択すると、Random Subset to New List ウィンドウが開きます。
- List Name フィールドに新しい名前を入力します。
- # of Samples per Class に値を入力します。この値はサンプルの総数より小さくなければなりません。
- Create を選択して新しいリストを生成します。
Concatenate Lists(リストの結合)
Concatenate を選択すると、Concatenate Lists ウィンドウが開き、選択したデータセットの名前が表示されます。
- List Name フィールドに新しい名前を入力します。
- Create を選択して結合されたリストを生成します。
Download as CSV(CSVとしてダウンロード)
表の右上にある Download オプションを選択して、サンプルリストを.csvファイルとしてダウンロードします。
Filtering Lists
サンプルリストをフィルタリングして特定の項目を見つけることができます。
- Filter アイコンをクリックして Filter Lists ページを開きます。
- 提供されたオプションを使用してリストをフィルタリングします:
- Name: 名前でリストを検索。
- Date Created: 日付範囲を選択するか、Today、Yesterday、Last 7 Days、Last 30 Days、Current Month、Previous Month、または Last Year などのプリセットオプションから選択します。Apply を選択して確認します。
- Data Shape: データ形状でリストをフィルタリング。
- Sample Rate: サンプルレートに基づいてリストを検索。
- フィルターフィールドに必要な情報を入力し、Apply をクリックして表示されるリストを絞り込みます。
Distribution
Distribution セクションでは、ソースファイルから作成されたセグメント化されたサンプルリストの視覚的および表形式の表現を提供します。これらのリストは、AI Exploration、Training、または Testing に使用できます。
サンプルリストの各行は、ソースファイルストリームから取得された固定長のラベル付き観測データを表します。
分布の表示
- 新しく作成されたセグメント化リストをクリックして、その内容を開きます。
- リストにはセグメント化されたデータブロック(_ウィンドウ_とも呼ばれます)が表示されます。
- 分布を視覚化するのに役立つデータのヒストグラムが表示されます。
- # of Bins フィールドを使用して、ヒストグラムの粒度を調整します。
- ビンの数を増減すると、ヒストグラムが動的に更新されます。
- Classes および Count フィールドは、変更を反映して自動的に調整されます。
- サンプルリストのグラフ表現を表示するには、Distribution セクションの右上にある グラフアイコン をクリックします。
- グラフはポップアップウィンドウに表示されます。
- 左側の表からサンプルリストを選択します。対応するグラフが右側に表示されます。
グラフの詳細
グラフポップアップには、以下の詳細情報が表示されます:
- Number of samples(サンプル数)
- Classes and sample counts(クラスとサンプルカウント)
- File name(ファイル名)
- Start and end times(開始および終了時間 - または値?)
- Target class(ターゲットクラス)
- Metadata fields(メタデータフィールド)
- Start and end values for each metadata field(各メタデータフィールドの開始値と終了値)
表内の行を選択すると、概要セクションとともに列ごとのグラフが表示されます。
マルチチャンネルおよびズーム機能
- 複数のデータチャンネルを同時に表示できます。
- 概要パネルはインタラクティブなズームをサポートしています。
- ズームインするには、概要内の目的のセクションをクリックしてドラッグします。
- ズームされた領域は、上のチャンネルグラフに表示されます。
- リセットするには、Reset Zoom をクリックします。
::: info NOTE セグメンテーション直後にヒストグラムが表示されない場合は、ページを更新してみてください。 :::