类别 (Classes)
类别 (Classes) 部分允许您通过以下三个选项卡创建和管理新的分类器:
- 数据样本列表 (Data Sample List)
- 列表分布 (Distributions for List)
- 列表探索结果 (Exploration Results for List)
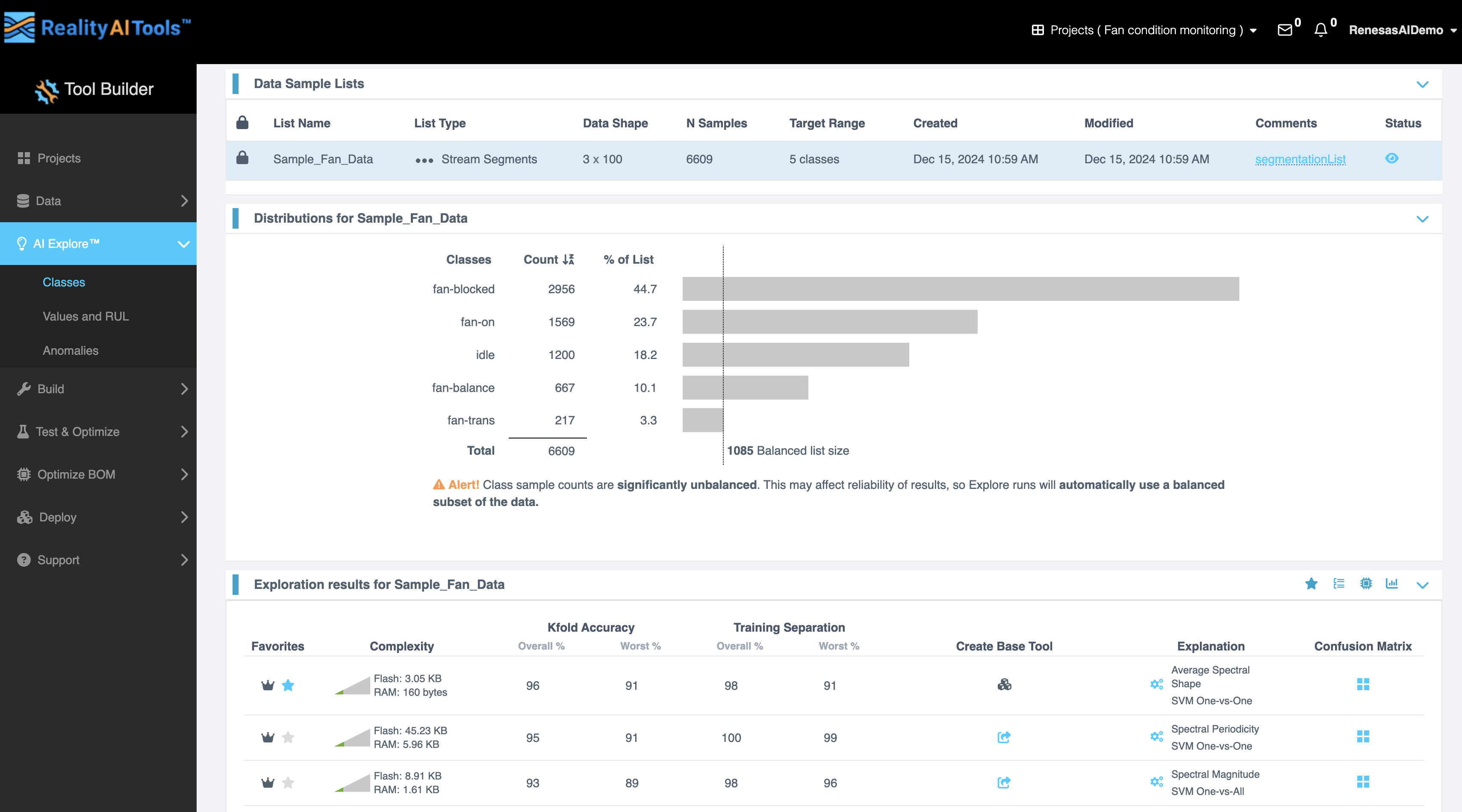
数据样本列表 (Data Sample List) 选项卡
此选项卡提供了一个详细的表格,显示数据样本列表的属性。
| 列 | 描述 |
|---|---|
| 锁定状态 (Lock Status) | 指示列表是否已锁定以进行编辑。 |
| 列表名称 (List Name) | 数据样本列表的名称。 |
| 列表类型 (List Type) | 列表的类型(例如,回归、分类)。 |
| 数据形状 (Data Shape) | 数据的形状(例如,行、列)。 |
| N 样本 (N Samples) | 列表中的样本数。 |
| 目标范围 (Target Range) | 目标值的范围。 |
| 创建时间 (Created) | 创建列表的日期和时间。 |
| 修改时间 (Modified) | 列表最后修改的日期和时间。 |
| 评论 (Comments) | 任何其他注释或观察结果。 |
| 状态 (Status) | 列表的当前状态(例如,活动、归档)。 |
列表分布 (Distributions for List) 选项卡
此选项卡显示所选列表中类别的分布。
- 表格中的列:
- 类别 (Classes): 数据中类别的名称。
- 计数 (Count): 每个类别中的样本数。
- 列表百分比 (% of List): 每个类别在整个列表中的比例。
- 功能:
- 分布的图形表示与数据一起显示。
- 还会显示总计数和平衡列表大小。
- 警报: 如果类别样本计数明显不平衡,将显示警报:
“类别样本计数明显不平衡。这可能会影响结果的可靠性,因此探索运行将自动使用数据的平衡子集。”
列表探索结果 (Exploration Results for List) 选项卡
点击 开始探索 (Start Exploring) 按钮。
探索结果界面 (Exploration Results Interface)
运行探索时,您可以使用提供的工具和选项监控结果并与之交互。在探索结果部分,每一行代表基于 AI 探索 (AI Explore) 运行期间识别出的不同特征的不同模型。本节概述了每个功能、其用途和使用说明。
后台发生的情况
当您点击 运行探索 (Run Explore) 按钮时,Reality AI 算法开始分析您的数据。该算法会生成多个针对您的分类问题量身定制的优化特征集和机器学习模型。然后,它仅显示表现最佳的结果。
算法的工作原理
- 平衡子集创建 该算法创建样本列表的平衡子集,确保每个类别具有相同数量的样本。如果样本列表非常大,它还可以对数据进行二次采样以减少处理时间。
- 特征和模型优化 该算法识别最有效的特征集和机器学习参数,以区分数据中的训练类别。在此过程中,它会评估数百个潜在的特征集和模型。
- 模型训练和验证 有前途的特征集用于构建机器学习模型,这些模型在平衡子样本上进行训练。这些模型经过 K 折交叉验证 (K-Fold Cross-Validation) 过程以评估其性能。
- 结果选择 仅显示表现最佳的模型和特征集,为您提供最有效的解决方案。
什么是 K 折验证?
K 折验证是一种通过将数据集划分为 K 个相等部分(折)来评估模型性能的方法。每个折用作测试集一次,而其余折用作训练。
例如,在 10 折交叉验证 (K=10) 中:
- 数据集被分为 10 个折。
- 在第一次迭代中,第 1 折用于测试,其余 9 个折用于训练。
- 在第二次迭代中,第 2 折用于测试,其余用于训练。
- 此过程持续进行,直到 10 个折中的每一个都已用作测试集一次。
Reality AI Tools 在 AI 探索 (AI Explore) 页面上使用 K=10 进行交叉验证,以确保稳健可靠的模型评估。
探索期间的关键操作
| 操作 | 描述 | 用途和效果 |
|---|---|---|
| 停止探索 (Stop Explore) | 点击此按钮终止探索过程。 | 停止探索,如果需要调整或测试时间过长,这很有用。 |
| 运行探索 (Run Explore) | 点击后,开始探索 (Start Explore) 按钮消失,探索开始。 | 启动探索过程。 |
| 星形图标 (Star Icon) | 运行探索后替换 + 图标。 | 点击以查看加星标的结果。 |
| 分组依据图标 (Group by Icon) | 打开包含特征空间和决策结构选项的下拉菜单。 | 特征空间:按详细特征(如声谱图、频谱特征、统计数据、样本数据和相位特征)对结果进行分组。 决策结构:按分类器类型(SVM、NN、CNN)对结果进行分组。这使得能够按特征属性或分类器方法进行分组,从而根据用户偏好简化数据分析。 |
| 微控制器图标 (Microcontroller Icon) | 打开 过滤探索结果 (Filter Exploration Results) 弹出窗口。 | 允许您选择目标设备并指定 Flash 和 RAM 大小等参数。 |
| 图表图标 (Graph Icon) | 点击以在数据的图形视图和表格视图之间切换。 | 显示针对复杂性调整的图形数据。再次点击切换到表格视图。 |
过滤探索结果
- 点击 微控制器图标 打开 过滤探索结果 弹出窗口。
- 从下拉菜单中选择目标设备。
- Flash 和 RAM 大小会自动填充,但可以手动编辑。
- 使用以下选项:
- 清除 (Clear):重置过滤器选择。
- 应用 (Apply):将所选过滤器应用于结果。
查看数据
探索数据最初以图形方式显示,并带有调整视图的选项。
| 图标 | 操作 | 效果 |
|---|---|---|
| 显示更多结果 (Show More Results) | 点击结果表底部的此按钮以将列表扩展到前三个结果之外。 | 显示更多探索结果。 |
| 显示较少结果 (Show Fewer Results) | 点击以将扩展的结果折叠回前三个。 | 简化视图以关注关键结果。 |
数据表字段
列 | 描述 |
|---|---|
收藏夹 (Favorites) | 点击星形图标将结果标记为收藏。 |
复杂性 (Flash/RAM) | 此字段显示每个结果的 Flash 和 RAM 要求,允许您评估各种配置的资源需求。
此信息有助于评估模型在资源受限环境中的适用性。 |
总体百分比 (Overall%) 和 最差百分比 (Worst%) | 显示 k 折交叉验证和训练分离的准确率百分比。 |
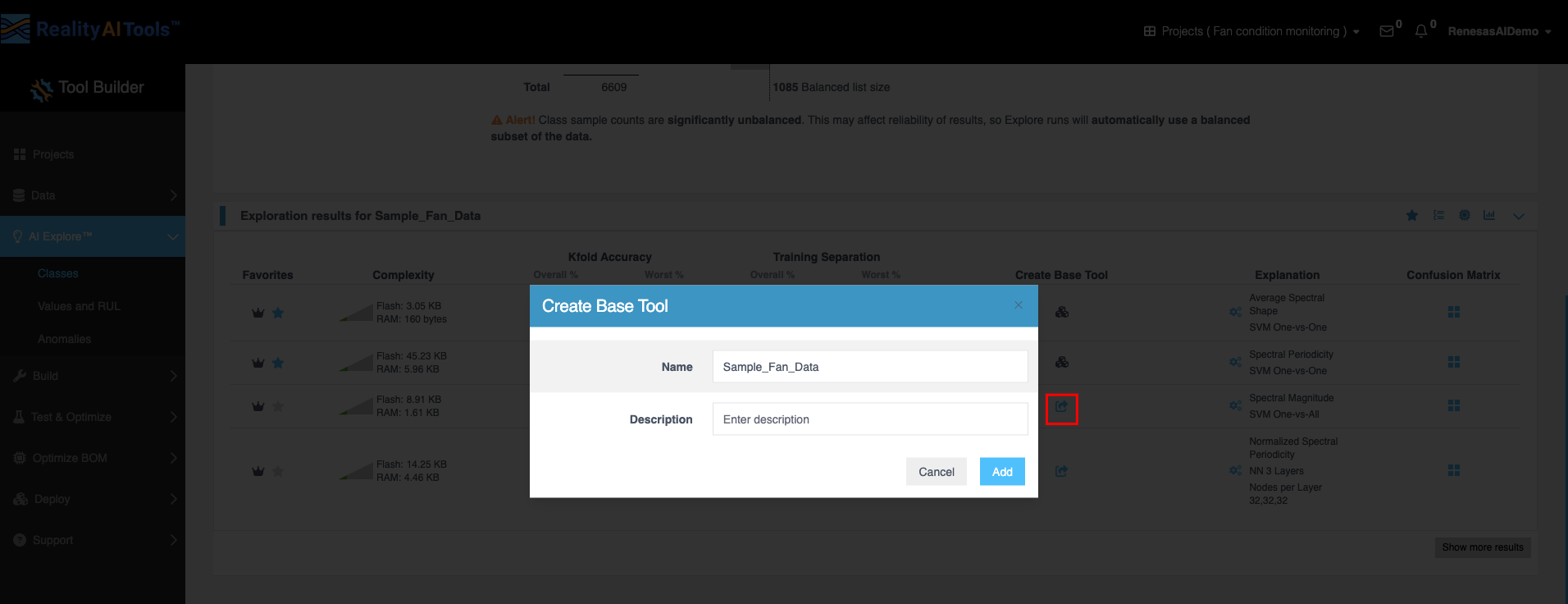
创建 基础工具 (Base Tool) | 允许您创建一个 基础工具 以进行进一步处理。基础工具 是能够从特定样本列表中包含的数据中学习的程序。基础工具 结合了:数据结构定义、解析/分段方法、特征选择、机器学习模型和输出类别定义。 |
解释 (Explanation) | 此字段通过交互式图表提供有关决策结构、决策重要性和类别重要性的见解。
这些可视化有助于解释模型的行为以及不同特征在其预测中的重要性。 |
混淆矩阵 (Confusion Matrix) | 打开 k 折和训练分离结果在实际类别和输出类别上的详细视图,提供详细的准确率和 F1 分数统计信息。 |
功能的详细描述
- 创建 基础工具 (Base Tool):
- 点击 创建 基础工具 列中的图标以打开窗口。
- 输入工具的名称和描述。
- 点击 添加 (Add) 保存工具。
- 完成此操作后,图标会发生变化。
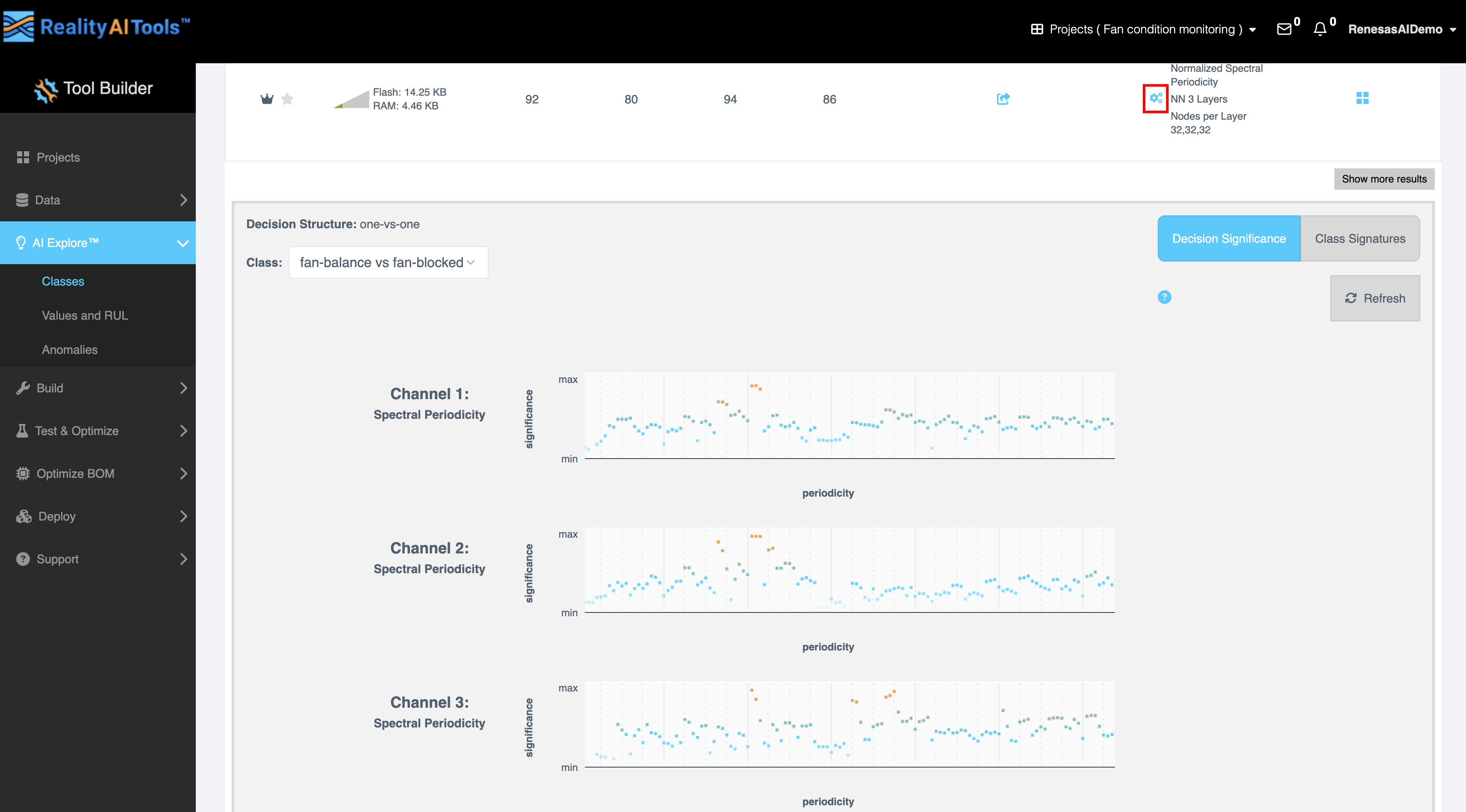
- 解释 (Explanation):
- 选择齿轮图标以查看:
- 决策结构 (Decision Structure):决策路径(一对一)的可视化表示。一对一是指机器学习模型中使用的分类策略,特别是对于多类分类任务。
- 类别 (Class):选择要生成图表的所需类别。
- 决策重要性 (Decision Significance):使用橙色(高重要性)和蓝色(低重要性)块显示特征的影响。具有较高橙色块的特征对于决策更为重要,表明它们对分类器性能的贡献很大。
- 类别重要性 (Class Significance):从下拉菜单中选择一个类别以分析其对结果的影响。
- 选择齿轮图标以查看:
- 混淆矩阵 (Confusion Matrix):
- 点击 混淆矩阵 列中的图标以打开矩阵。
- 查看实际类别和输出类别的 k 折和训练分离数据。
- 选择三种矩阵变体之一。
- 第一个选项显示带有总体准确率和 F1 分数的空白 混淆矩阵。
- 第二个选项显示每个类别/分类的准确率。
- 第三个选项显示错误百分比、混淆以及详细的精确率和召回率数字。
- 点击 剪贴板图标 (Clipboard Icon) 以复制矩阵数据供外部使用。
