值和剩余使用寿命 (Values and RUL)
值和 RUL (Values and RUL) 部分使您能够有效地处理回归数据。RUL 代表 剩余使用寿命 (Remaining Useful Life),这是预测建模中的一个关键指标,用于估算系统或组件在需要维护或更换之前将运行多长时间。本节分为三个部分:
- 数据样本列表 (Data Sample List)
- [列表名称] 的分布 (Distributions for [List Name])
- [列表名称] 的探索结果 (Exploration Results for [List Name])
每个部分都提供独特的功能和见解,帮助您分析和完善用于模型开发的回归数据。
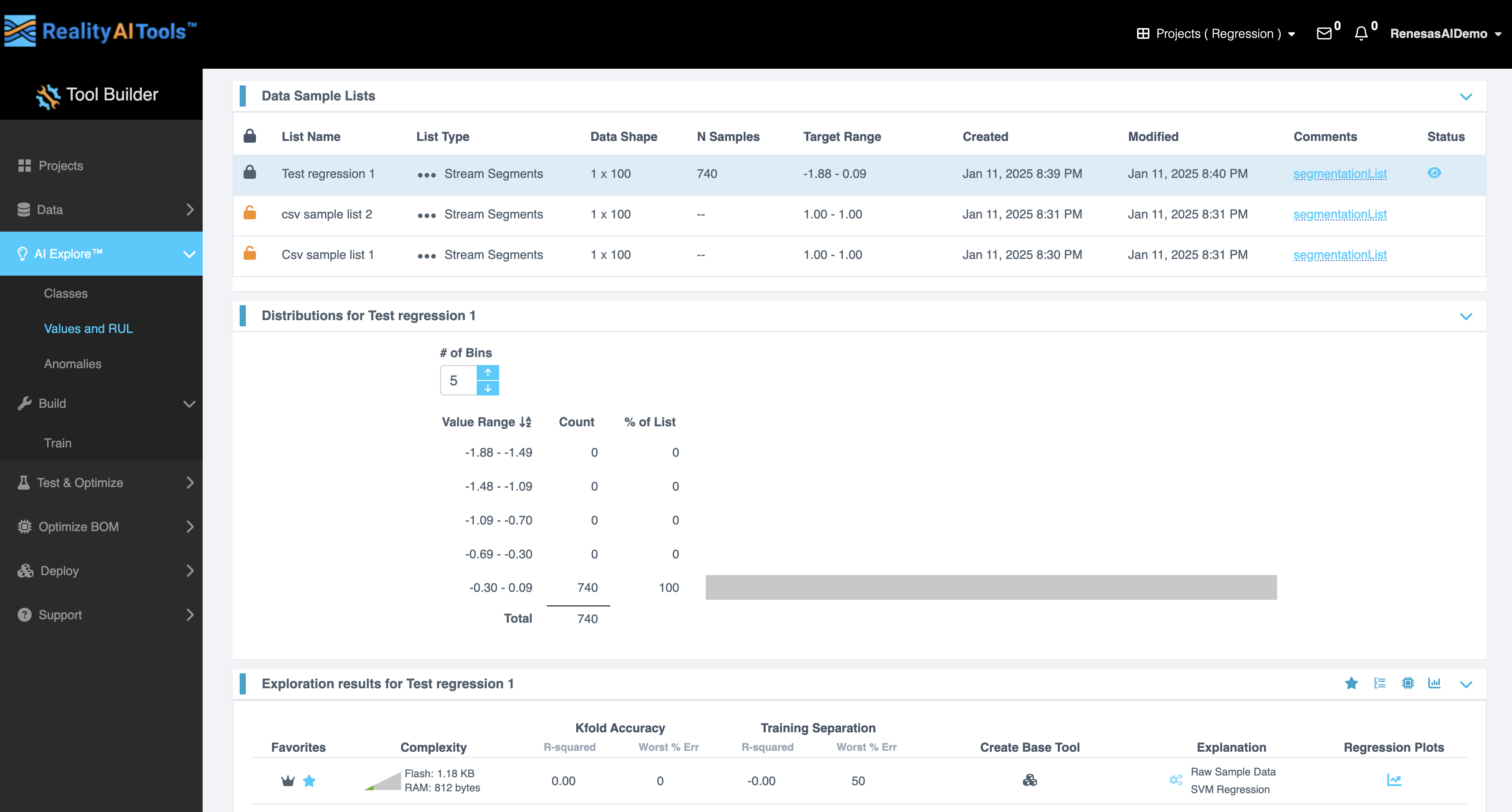
数据样本列表 (Data Sample List)
数据样本列表 部分显示一个包含以下字段的交互式表格:
| 字段 | 描述 |
|---|---|
| 锁定符号 (Lock Symbol) | 允许您锁定或解锁特定数据样本以防止意外编辑。 |
| 列表名称 (List Name) | 显示当前数据样本列表的名称。 |
| 列表类型 (List Type) | 指定列表是用于训练、验证还是测试目的。 |
| 数据形状 (Data Shape) | 以特征和样本的形式指示数据的维度。 |
| N 样本 (N Samples) | 显示数据列表中的样本数。 |
| 目标范围 (Target Range) | 显示数据中目标值的范围。 |
| 创建时间 (Created) | 显示数据列表创建的日期和时间。 |
| 修改时间 (Modified) | 显示数据列表最后一次修改的日期和时间。 |
| 评论 (Comments) | 包括与数据列表相关的任何注释或备注。 |
| 状态 (Status) | 指示数据列表的当前状态,例如就绪、进行中或锁定。 |
此表帮助您有效地组织、审查和管理您的回归数据。
分布 (Distributions)
分布 部分可视化数据样本的分布,提供有关数据集特征的关键见解。它包括:
| 字段 | 描述 |
|---|---|
| 箱数 (# of Bins) | 指定直方图的箱数。您可以手动输入值或使用向上和向下箭头进行调整。 |
| 值范围 (Value Range) | 显示所选箱中的值范围。 |
| 计数 (Count) | 指示每个箱内的样本数。 |
| 列表百分比 (% of List) | 显示每个箱内样本占总样本的百分比。 |
| 总计数 (Total Count) | 显示数据列表中的样本总数。 |
此部分允许您分析数据分布模式并识别异常或不平衡。
探索结果 (Exploration Results)
探索结果 部分提供详细的指标和可视化效果,以评估您的回归数据。关键功能包括:
| 字段 | 描述 |
|---|---|
| 收藏夹 (Favorites) | 允许您标记首选配置或结果以便快速访问。 |
| 复杂性 (Complexity) | 显示计算复杂性,包括针对不同配置的 Flash 和 RAM 等资源需求。 |
| K 折准确率 (Kfold Accuracy) | 显示交叉验证准确率指标,包括 R 平方 (R-squared) 和 最差误差百分比 (Worst% Error) 值。 |
| 训练分离 (Training Separation) | 提供训练数据的性能指标,包括 R 平方 (R-squared) 和 最差误差百分比 (Worst% Error) 值。 |
| 创建 基础工具 (Base Tool) | 允许您创建基线工具或模型配置以进行进一步分析。 |
| 解释 (Explanation) | 提供对决策结构和各种参数重要性的见解,以及用于更深入分析的交互式图表。 |
| 回归图 (Regression Plots) | 显示散点图或折线图等可视化效果,以表示回归输出及其与目标值的一致性。 |
此部分对于在部署之前完善模型和了解其性能至关重要。
创建 AI 模型并查看统计数据
此过程指导您使用上传的数据集创建 AI 模型并查看这些模型的各种统计数据。
- 在左侧菜单中,转到 AI 探索 (AI Explore) > 值和 RUL (Values and RUL)。
- 在 数据样本列表 部分,从表中选择所需的分段列表。
- 在 探索结果 选项卡中,点击 开始探索 (Start Exploring)。
- 系统开始处理特征空间并生成模型。
- 您可以监控进度并查看列出的表现最佳的模型。
- 有关此阶段的更多信息,请参阅 探索结果界面 部分。
- 探索结果 部分中的每一行代表基于 AI 探索过程中识别出的特征的模型。要查看详细的准确率统计数据,请点击所需模型的 回归图 (Regression Plots) 行。
- 空白的 回归图 打开。在屏幕底部:
- 点击 第一个选项 查看 混淆矩阵 (confusion matrix),其中包括总体准确率、F1 分数和误差分布。
- 使用误差分布图识别误差在数值范围内的集中情况。分布越宽表明模型性能越差。
- 点击 第二个选项 访问两个图表:
- 回归图 (Regression Plot): 显示所选模型的实际值与预测值。
- 残差误差图 (Residual Error Plot): 显示逐样本的残差误差。
- 点击 第一个选项 查看 混淆矩阵 (confusion matrix),其中包括总体准确率、F1 分数和误差分布。
注意
关键指标包括:
- 残差误差 (Residual Error): 数据点与回归线之间的垂直差异,代表预测值与观察值之间的误差。
- R 平方 (R-squared, R²): 衡量自变量解释因变量变化的程度。值越高表明拟合越好。
- 平均绝对误差 (Mean Absolute Error, MAE): 所有绝对误差的平均值,代表平均误差幅度。
- 将鼠标悬停在 复杂性 (Complexity) 选项卡上以查看模型的资源消耗:
- 特征空间 (Feature Space): 特征计算的乘法运算。
- 分类器 (Classifier): 分类器所需的乘法运算(回归模型为空)。
- 总计 (Total): 总乘法运算。
- 使用复杂性数字来衡量目标处理器 (MCU/MPU) 上模型的资源需求。例如:
- 如果基于频谱的特征很重要,并且决策重要性图突出显示 50 Hz 以下的频率,则在特征计算期间应用 < 50 Hz 的滤波器可以减少资源消耗。
- 如果您在项目创建期间预选了目标处理器,则表现最佳的模型将与该处理器的可用资源保持一致。
- 查看统计数据后,点击突出显示的选项以部署模型进行进一步测试或导出。