整理 (Curate)
- Version 5.6.6
- Version 6.0
Introduction
整理 (Curate) 页面是执行大部分预处理工作的地方。在这里,所有源文件将被解析为大小一致的离散样本。然后,所有样本将被添加到样本列表中。本节包含两个子选项卡:源文件 (Source Files) 和 数据样本列表 (Data Sample Lists)。
- 源文件:这是您管理项目期间收集的原始数据的地方。
- 数据样本列表:在这里,您从可用的源文件创建更小的、精选的数据集。
当长时间收集数据时,生成的文件对于内存和处理能力有限的微控制器单元来说通常太大。这些设备旨在处理较小的、集中的数据集,使其能够仅处理发生有意义事件的关键实例。
整理 (Curate) 页面通过将大数据文件分解为更小的、可管理的部分来帮助实现这一目标。此过程确保模型可以被有效地训练以模拟现实世界的场景,优化其在受限环境中的部署性能。分解数据文件很重要,因为这些块将成为您的 ML 模型的输入。例如,如果您的数据文件长 10 秒,您可以将其分解为 10 个分段,每个分段长 1 秒。我们可以根据用例的先验知识选择这些分段的长度,或者从 1 秒的窗口长度开始并从那里进行实验。
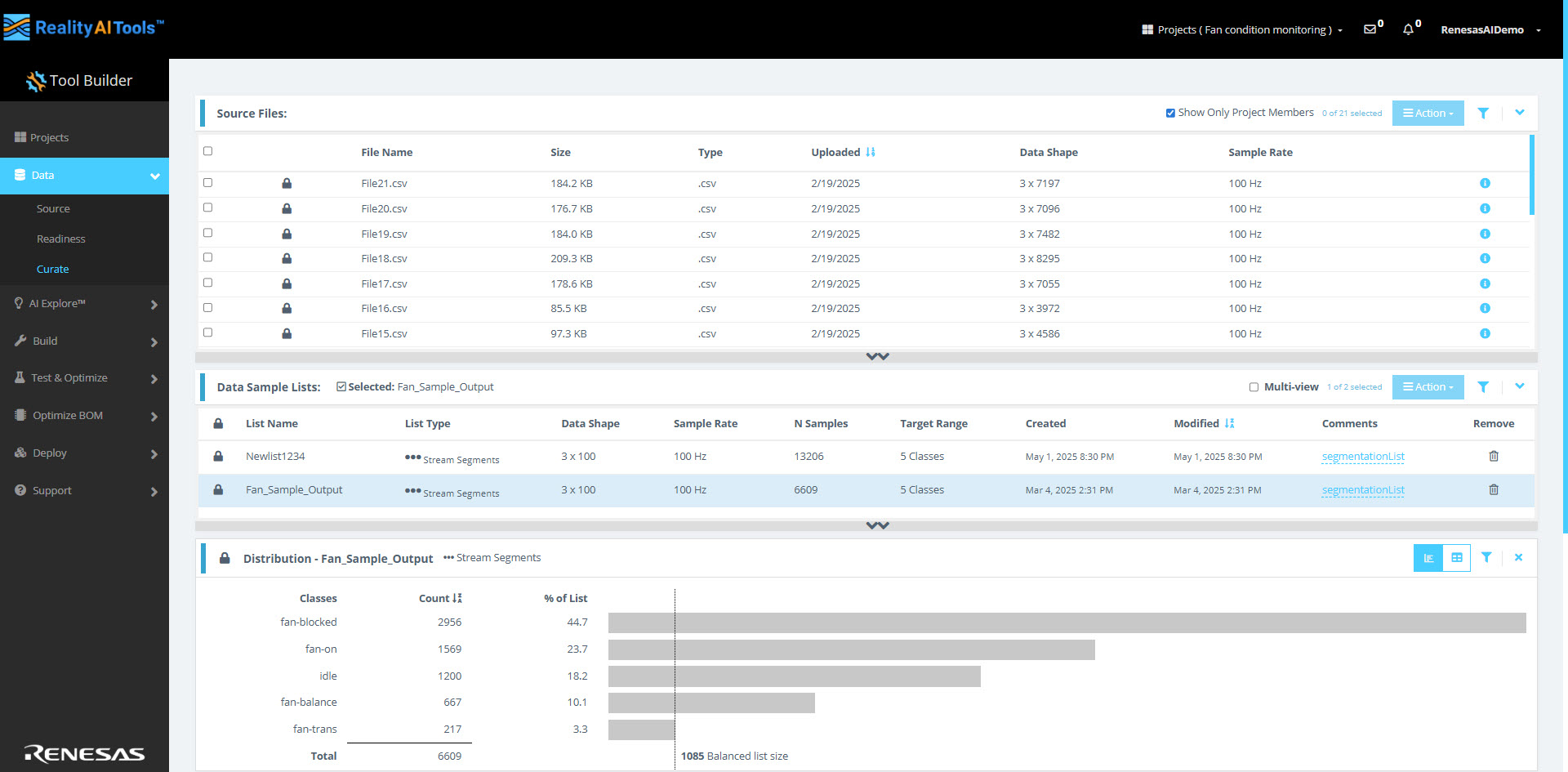
Source Files
在这里,您可以查看所有上传的数据文件及其文件名、大小、类型、上传日期、数据形状和采样率。
Viewing Project Members
选择 仅显示项目成员 (Show Only Project Members) 复选框以过滤显示的源文件,将视图限制为仅与项目成员关联的文件。
Actions
在 操作 (Action) 下拉菜单中,您将找到以下选项:
- 全选 (Select All): 选择列出的所有文件。
- 取消全选 (Deselect All): 清除所有选定的文件。
- 从所选新建列表 (New List From Selected): 使用选定的文件创建一个新列表。
- 从所选分段列表 (Segment List From Selected): 从选定的文件创建一个分段列表。
- 编辑元数据类型 (Edit Metadata Type): 修改选定文件的元数据类型。
- 格式化所选 (Format Selected): 定义或更新选定文件的文件格式。
- 移除所选 (Remove Selected): 从项目中移除选定的文件。
- 导入元数据 (Import Metadata): 上传元数据文件以添加或更新源文件的元数据。
- 关闭 (Close): 退出操作菜单而不进行更改。
Creating a Segmented List
标记文件后,您可以创建一个分段列表,将数据划分为更小的、可管理的样本以进行分析和训练。请按照以下步骤有效地配置分段方法和选项。
为什么要分段?
分段在生成针对资源受限环境(例如使用微控制器 (MCU) 的环境)部署进行优化的模型方面起着至关重要的作用。这些模型旨在快速高效地处理实时数据,通常在很小的时间窗口内(例如 1 秒、500 毫秒甚至更短的持续时间)。
在实际应用中,模型需要基于短而连续的数据流而不是长且不间断的记录来进行预测。为了在训练阶段复制这种情况,原始数据被分为更小的分段。然后使用这些分段来训练模型,使其能够学习并适应在实时生产环境中将遇到的数据类型。
这种方法确保模型在实时场景中有效执行,同时在有限的处理能力和内存限制下运行。
创建分段列表的步骤
- 转到 操作 (Actions) > 从所选分段列表 (Segment List from Selected)。
- 分段文件 (Segment Files) 窗口打开,显示选定用于分段的文件。
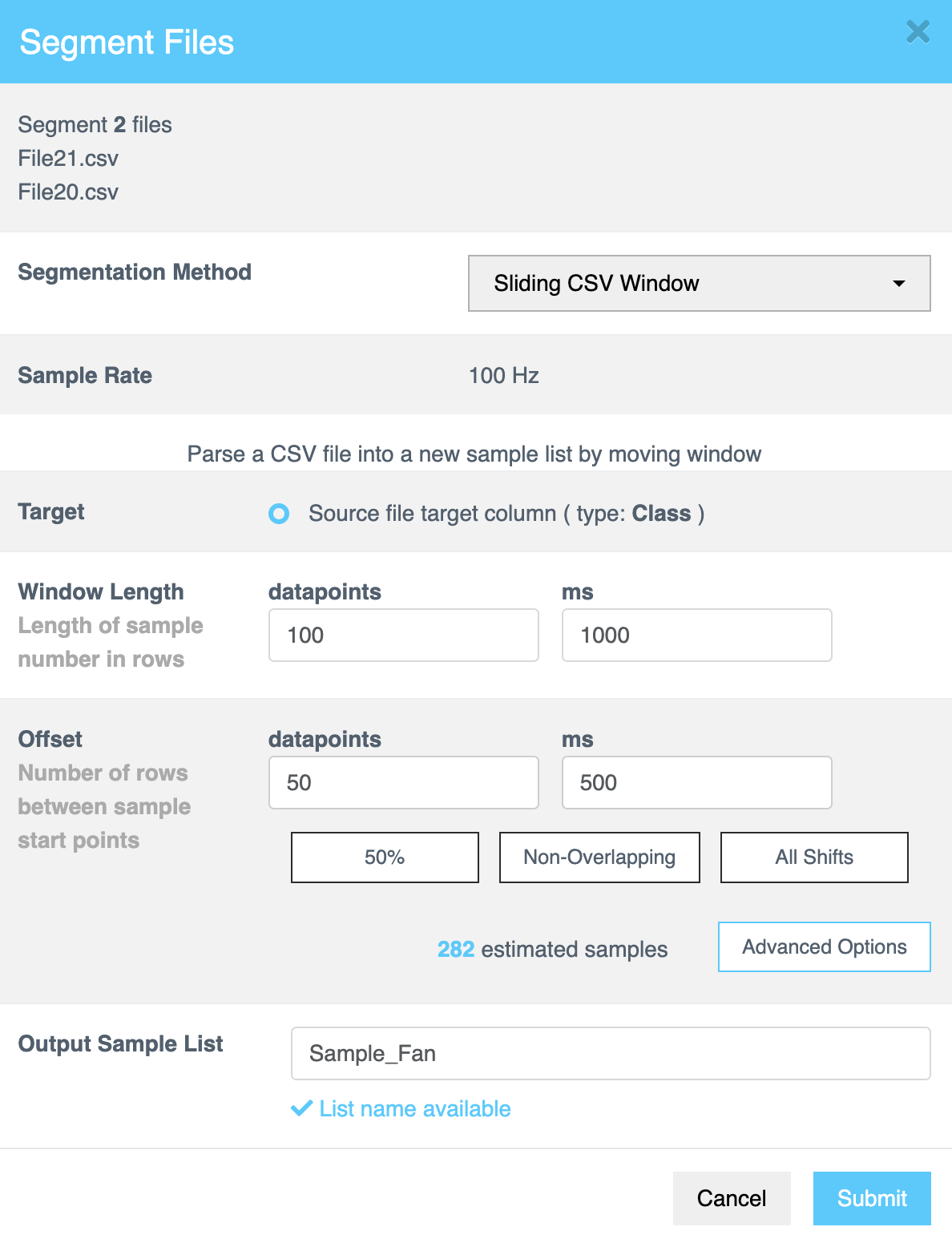
- 从 分段方法 (Segmentation Method) 下拉菜单中,选择以下方法之一:
- 滑动 CSV 窗口 (Sliding CSV Window)
- 能量触发 (Energy Triggered)
滑动 CSV 窗口配置
滑动 CSV 窗口 方法使用逐步滑动窗口方法在整个文件中将 CSV 数据 [数值、基于文本或时间序列数据] 划分为更小的、可管理的样本,在每一步捕获数据,直到处理完整个文件。下表总结了此方法可用的配置选项:
选项 | 描述 |
|---|---|
采样率 (Sample Rate) | 显示将 CSV 文件解析为样本列表的固定采样率。此值在文件格式化期间是固定的。 |
目标 (Target) | 从文件元数据中选择目标列(类型:类别)。 |
窗口长度 (Window Length) | 窗口长度 决定了用于分段的决策窗口的大小。以行或毫秒 (ms) 为单位指定每个样本的长度。此值控制 AI 分析多少数据来对每个分段进行分类。 提示: 尝试不同的窗口长度以确定数据集的最佳配置。 |
偏移量 (Offset) | 偏移量 指定源文件中连续样本起始点之间的间隔。以行或毫秒 (ms) 为单位输入值,以定义解析器在创建新样本窗口之前移动的距离。 |
50% 重叠 (50% Overlap) |
|
无重叠 (Non-Overlapping) |
|
所有移位 (All Shifts) |
|
高级选项
点击 高级选项 (Advanced Options) 进一步自定义分段。
| 选项 | 描述 |
|---|---|
| 重启流式窗口 (Restart Streamed Window) | 在每个类别或元数据块的开头重新启动窗口。 |
| 尊重过渡 (Respect Transitions):确保处理类别或元数据块内的过渡。 | |
| 类别 (Class):专门处理类别块内的过渡。 | |
| 保留短窗口样本 (Keep Short Window Samples) | 确定如何处理文件或类别块末尾的短样本。 |
| 保留短样本 (Retain Short Samples):在输出中包含短样本。 | |
| 每块 1 个 (1 per Block):每块保留一个短样本。 | |
| 输出类型 (Output Type) | 选择如何保存分段样本: |
| 输出到新列表 (Output to New List):为分段样本创建一个新列表。 | |
| 追加到现有列表 (Append to Existing List):将解析的样本添加到现有列表。 |
Explorer 层级有一个限制,即创建的分段列表包含的样本不得超过 7,000 个。
输出样本列表
配置分段后,在 输出样本列表 (Output Sample List) 页面上为分段样本列表提供一个名称。此字段为必填项。
| 操作 | 描述 |
|---|---|
| 提交 (Submit) | 确认配置并完成该过程。 |
点击提交后,等待约 30 秒并刷新页面。刷新页面后,点击数据样本列表选项卡。点击该选项卡后,您应该能够看到已完成处理的列表。
分段/分解此数据集需要 < 1 分钟。但是,分段的持续时间取决于数据集的大小。例如:1 GB 的文件可能需要 5-10 分钟来分段。
能量触发 (Energy triggered)
当您选择能量触发选项时,您可以根据需要配置以下设置。此分段方法特别适用于回归数据集(如基于音频的信号)。
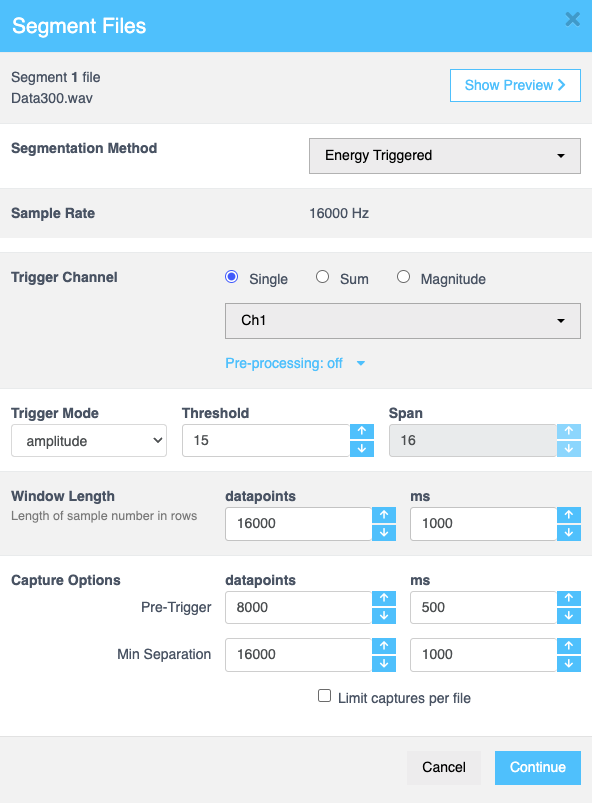
| 字段 | 描述 |
|---|---|
| 显示/隐藏预览 (Show/Hide Preview) | 显示数据文件的概览,包括文件名、所选类别、触发点、捕获窗口和数据的图形表示。此功能允许您刷新预览、设置数据的起点和终点、在图形表示内平移和缩放,以及查看完整文件以进行全面分析。 |
| 采样率 (Sample Rate) | 设置数据采样的频率。对于能量触发事件,这会自动设置为 100 Hz 以确保准确的数据捕获。无需手动输入。此项在文件格式化期间固定。 |
| 触发通道 (Trigger Channel) | 确定触发检测的源。选项包括: |
| - 单通道 (Single):从下拉菜单中选择特定通道以监控能量触发事件 | |
| - 求和 (Sum):允许您通过数学方式组合通道(例如,和或差)以定义跨多个通道的触发条件。 | |
| - 幅度 (Magnitude):通过计算组合幅度,实现同时监控多个通道。 | |
| 预处理 (Pre-Processing) | 配置数据归一化。选中 归一化 (Normalize) 复选框以启用此选项。这将缩放数据以确保统一性并改进样本之间的比较。 |
| 归零 (Zeroing) | 调整数据处理的归零方法。选项包括: |
| - 无 (None): 保留原始数据而不应用任何归零调整。 | |
| - 去最小值 (DeMin): 通过减去最小值来调整数据基线。 | |
| - 去均值 (DeMean): 通过减去均值将数据居中,确保分析时数据以零为中心。 | |
| 零窗口 (Zero Window) | 指定应用归零调整的持续时间。帮助管理所选窗口内的基线漂移。输入所需的值或使用向上和向下箭头进行调整。 |
| 滤波器 (Filter) | 设置数据处理的滤波器类型。选项包括: |
| - 无 (None): 不对数据应用滤波器。 | |
| - 低通 (Low): 应用低通滤波器以去除高频噪声,保留低频进行分析。 | |
| - 带通 (Band): 应用带通滤波器以隔离指定范围内的频率,去除该频带之外的频率。 | |
| - 高通 (High): 应用高通滤波器以去除低频噪声,保留高频进行分析。 | |
| 触发模式 (Trigger Mode) | 确定触发的模式。选项包括: |
| - 幅度 (Amplitude): 基于数据的幅度(信号强度)检测触发。 | |
| - 正交叉 (+ Crossing): 当信号穿过正阈值时触发。 | |
| - 负交叉 (- Crossing): 当信号穿过负阈值时触发。 | |
| - RMS: 使用均方根 (RMS) 值进行触发检测,关注信号中的总能量。 | |
| - RMS 阶跃 (RMS Step): 基于 RMS 值的阶跃变化触发。 | |
| - RMS 阶跃比 (RMS Step Ratio): 基于连续 RMS 阶跃变化的比率检测触发。 | |
| - 峰值 RMS 比 (Peak to RMS Ratio): 基于峰值信号值与其 RMS 值的比率触发,用于识别瞬态信号。 | |
| - 差分 (Diff): 基于连续数据点之间的差异检测触发。 | |
| - 符号 (Sign): 监控信号的符号(正或负)以进行触发检测。 | |
| 阈值 (Threshold) | 指定触发事件所需的最小信号电平。输入所需的值或使用向上和向下箭头。 |
| 跨度 (Span) | 定义触发检测的持续时间或范围。如果在触发模式中选择了 幅度 (Amplitude)、差分 (Diff) 或 符号 (Sign),则此字段不活动。 |
| 窗口长度 (Window Length) | 设置用于分析的一行中的样本数。帮助控制捕获数据的分辨率。直接输入值或使用向上和向下箭头进行调整。 |
| 数据点 (Datapoints) | 指定所选窗口内要分析的数据点数量。输入所需的值或使用向上和向下箭头进行调整。 |
| 毫秒 (ms) | 以毫秒为单位定义时间分析的窗口长度。输入所需的值或使用向上和向下箭头进行调整。 |
| 捕获选项 (Capture Options) | 配置用于捕获数据的预触发或最小间隔值: |
| - 预触发 (Pre-Trigger):确定触发事件发生前捕获的数据量,有助于了解事件前的情况。 | |
| - 最小间隔 (Min Separation):确保连续触发事件之间的最小间隔,以避免捕获冗余数据。 | |
| 限制每个文件的捕获数 (Limit Captures Per File) | 限制单个文件中存储的捕获数量,以管理文件大小并改进数据组织。选中复选框以激活此选项。 |
点击 继续 (Continue) 以填写更多详细信息,如下所示:
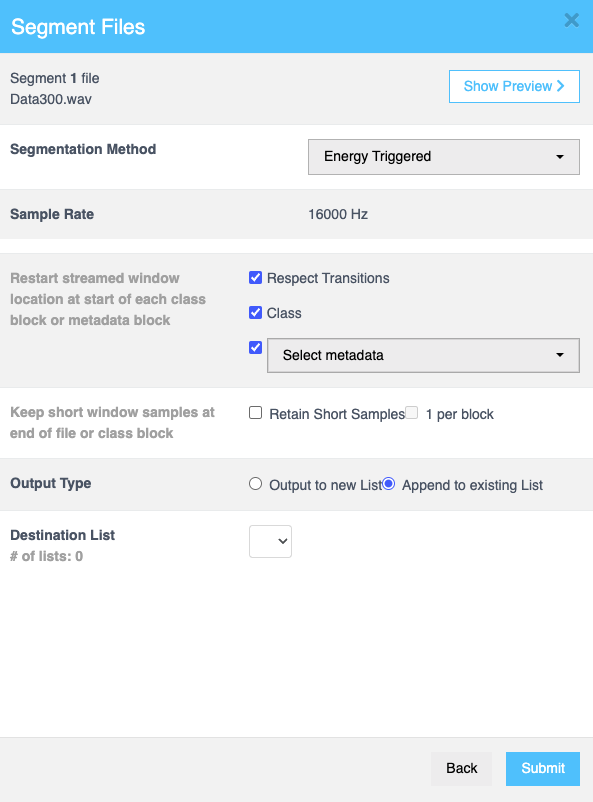
| 字段 | 描述 |
|---|---|
| 在每个类别块或元数据块的开头重新启动流式窗口位置 | 当您选中 尊重过渡 (Respect Transitions) 复选框时,类别 (Class) 和 元数据 (Metadata) 复选框变为可编辑状态。如果您选择 元数据,将出现一个下拉菜单,允许您指定所需的元数据。 |
| 在文件或类别块的末尾保留短窗口样本 | 选中 保留短样本 (Retain Short Samples) 复选框以保留文件或类别块末尾的短样本。您还可以启用 每块 1 个 (1 per block) 复选框以保留每块一个短样本。 |
| 输出类型 | 使用单选按钮在 输出到新列表 (Output to new List) 或 追加到现有列表 (Append to existing List) 之间进行选择,以确定是创建新列表还是将结果添加到现有列表。 |
| 输出样本列表 | 如果选择 输出到新列表,则此字段可用。输入将保存已处理样本的输出列表的名称。 |
| 目标列表 | 如果选择 追加到现有列表,则此字段可用。从下拉菜单中选择所需的列表。 |
点击 提交 (Submit) 确认。
Filtering Source Files
- 点击 过滤器 (Filter) 图标打开 过滤源文件 (Filter Source Files) 页面。
- 使用可用的过滤器缩小搜索范围:
- 名称 (Name): 按名称搜索文件。
- 数据类型 (Data Type): 基于数据类型进行过滤。
- 日期 (Date): 按文件创建或修改日期过滤。
- 数据形状 (Data Shape): 根据数据形状缩小文件范围。
- 采样率 (Sample Rate): 按采样率过滤。
- 未格式化 (Unformatted): 查找尚未格式化的文件。
- 已分配目标 (Assigned Targets): 过滤已分配目标的文件。
- 未分配目标 (Unassigned Targets): 定位未分配目标的文件。
- 填写必填字段后,点击 应用 (Apply) 以过滤源文件。
Defining the Target Class
要为您的数据定义目标类别,您有两个选项:
- 在源文件中使用附加列: 上传源文件时,包含一个额外的列来指定每个数据点的标签。
- 使用元数据文件: 准备一个名为 metadata 的 CSV 文件,其中包含以下两列:
-
- 文件名 (File Name): 您已上传的所有文件名的列表。
- 标签类型 (Label Type): 每个文件对应的标签。
- 文件名 (File Name): 您已上传的所有文件名的列表。
-
例如,如果您有 10 个“苹果”文件和 5 个“橙子”文件,请在元数据文件中相应地分配标签。
导入元数据
- 在 整理 (Curate) 页面上的 源文件 (Source Files) 选项卡中,使用 操作 (Action) > 导入元数据 (Import Metadata) 选项上传元数据文件。
- 将出现一个对话框,允许您拖放准备好的 CSV 文件。
- 从第二行下拉菜单中选择目标值 (Target Value)。保持第一行下拉菜单为文件名 (File Names)。这将根据分配的元数据标记文件。
- 上传后,描述性元数据将添加到源文件中。
查看目标类别
导入元数据后,展开 采样率 (Sample Rate) 行旁边的箭头。Amps 列将显示所有文件的目标类别选择。
这种方法在处理大批量文件时特别有用,因为手动向每个源文件添加附加列可能会很繁琐。
Data Sample Lists
本节说明如何使用 输出样本列表 (Output Sample Lists),这些列表是在执行 从所选分段列表 操作后生成的。这些列表以表格格式显示,包含以下详细信息:
| 字段 | 描述 |
|---|---|
| 列表名称 (List Name) | 样本列表的名称。 |
| 列表类型 (List Type) | 指定列表的类型,例如分类或回归。 |
| 数据形状 (Data Shape) | 列表中数据的形状或维度。 |
| 采样率 (Sample Rate) | 采集样本的速率。 |
| N 样本 (N Samples) | 列表中的样本数。 |
| 目标范围 (Target Range) | 列表中的目标值范围。 |
| 已创建 (Created) | 列表创建的日期和时间。 |
| 已修改 (Modified) | 列表最后更新的日期和时间。 |
| 评论 (Comments) | 允许您添加有关数据样本列表的评论或注释。 |
| 移除 (Remove) | 允许您从表中删除特定的样本列表。 |
Multi-view Option
在工具栏中,选中 多视图 (Multi-view) 复选框以更有效地比较和分析列表,您可以在多个视图中显示它们。
Actions
使用 操作 (Actions) 下拉菜单来管理样本列表。以下操作可用:
| 操作 | 描述 |
|---|---|
| 取消全选 (Deselect All) | 清除所有选定的项目。 |
| 随机子集到新列表 (Random Subset to New) | 从所选项目的随机子集创建一个新列表。 |
| 编辑传感器组 (Edit Sensor Groups) | 调整选定列表的传感器分组。 |
| 转换为回归列表/分类列表 (Convert to Regression List/Convert to Classification List) | 将选定的分类列表转换为回归列表,反之亦然。 |
| 重新映射类别 (Remap Classes) | 重新分配选定列表中的类别标签。 |
| 导出到 CSV (Export to CSV) | 将选定的列表保存为 CSV 文件。 |
| 从 CSV 导入 (Import From CSV) | 上传 CSV 文件以添加或更新数据样本列表。 |
| 关闭 (Close) | 退出操作菜单而不进行更改。 |
| 移除所选 (Remove Selected) | 删除选定的数据样本列表。 |
Filtering Lists
您可以过滤样本列表以查找特定项目。
- 点击 过滤器 (Filter) 图标打开 过滤列表 (Filter Lists) 页面。
- 使用提供的选项根据以下条件过滤列表:
- 名称 (Name): 按名称搜索列表。
- 列表类型 (List Type): 按类型过滤列表。
- 创建日期 (Date Created): 根据创建日期缩小列表范围。
- 数据形状 (Data Shape): 按数据形状过滤列表。
- 采样率 (Sample Rate): 根据采样率搜索列表。
- 在过滤字段中输入所需信息,然后点击 应用 (Apply) 以细化显示的列表。
Distribution
从源文件分段创建的样本列表可用于 AI 探索、训练或测试。每一行包含取自源文件流的特定长度的特定标记样本或观测值。
点击新创建的分段列表以查看其内容。此列表显示分段数据的块或窗口。数据的直方图也应出现以进行可视化。
如果分段后直方图没有立即出现,请尝试刷新页面。
您可以在 列表视图 (List View) 或 表格视图 (Table View) 中分析选定列表的分布。
视图选项
| 视图 | 描述 |
|---|---|
| 列表视图 (List View) | 按 类别 (Classes)、计数 (Count) 和 列表百分比 (% of List) 显示分布详情。 |
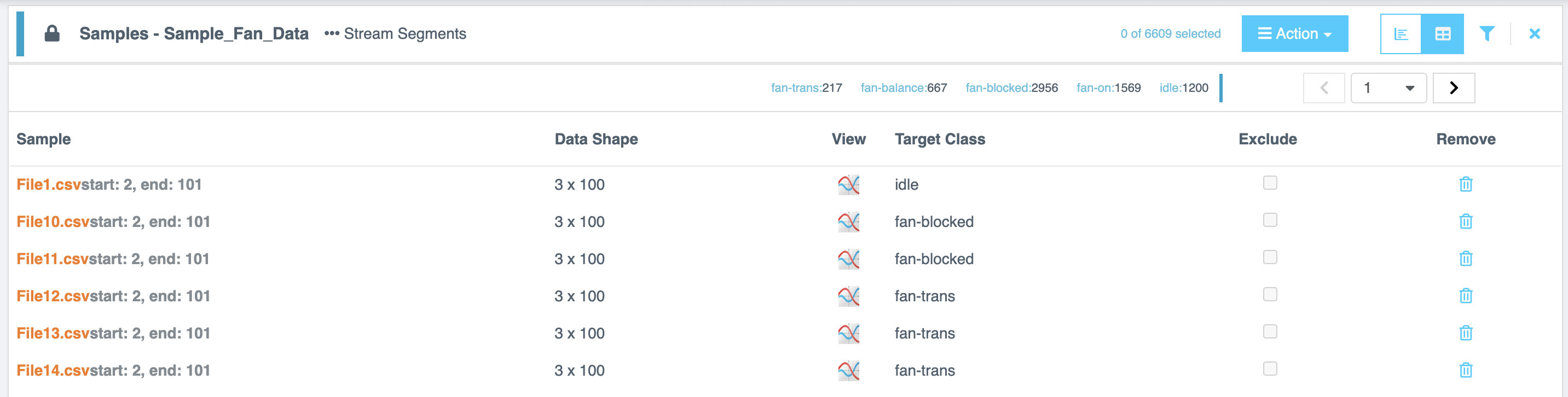
| 表格视图 (Table View) | 提供每个样本的详细信息,包括 样本文件 (Sample File)、数据形状 (Data Shape)、视图 (View)、目标类别 (Target Class) 下拉菜单(用于查找或创建类别)以及 排除 (Exclude) 和 移除 (Remove) 选项 |
在表格视图中执行操作
- 选择工具栏中的 操作 (Action) 按钮。
- 从以下选项中选择:
| 操作 | 描述 |
|---|---|
| 转移 (Transfer) | 将选定的项目转移到不同的列表。 |
| 转移到新列表 (Transfer to New List) | 从选定的项目创建一个新列表。 |
| 全选 (Select All) | 选择所有项目。 |
| 选择当前页所有 (Select All on Page) | 选择当前页面上显示的所有项目。 |
| 选择随机子集 (Select Random Subset) | 选择项目的随机子集。 |
| 取消全选 (Deselect All) | 清除所有选择。 |
| 为所选设置目标 (Set Target for Selected) | 为选定的项目分配目标类别。 |
| 排除所选 (Exclude Selected) | 从列表中排除选定的项目。 |
| 包含所选 (Include Selected) | 包含以前排除的项目。 |
| 导出到 CSV (Export to CSV) | 将选定的项目保存为 CSV 文件。 |
| 导入 CSV (Import CSV) | 从 CSV 文件导入项目。 |
| 关闭 (Close) | 退出操作菜单而不进行更改。 |
| 移除所选 (Remove Selected) | 删除选定的项目。 |
Introduction
整理 (Curate) 页面是在 AI 探索、训练或测试之前执行大多数预处理工作的地方。在此页面上,源文件被解析为大小一致的离散样本,并且这些样本被分组到样本列表中。
整理 页面包含三个主要选项卡:
- 项目文件 (Project Files) - 查看上传的文件,管理元数据,并准备用于数据集的文件。
- 数据集 (Data Sets) - 将文件组合成数据集,配置分段参数,并管理传感器组。
- 样本列表 (Sample Lists) - 生成和管理用于模型训练和评估的精选样本子集。
当长时间收集数据时,文件可能会变得太大,无法在内存和处理能力有限的微控制器单元 (MCU) 上高效处理。这些设备针对较小的、集中的数据集进行了优化,仅捕获最有意义的事件。
整理 页面通过将大数据文件分解为更小的、可管理的分段来解决这一挑战。这些分段模拟了部署在 MCU 上的模型的真实运行条件,即在实时数据的可滑动小窗口上连续进行预测。
例如,一个 10 秒的数据文件可以分为 10 个分段,每个分段 1 秒。分段长度的选择取决于用例。您可以使用领域知识(例如,持续 200 毫秒的振动模式)或从默认的 1 秒开始,并尝试更短或更长的窗口以优化模型准确性。
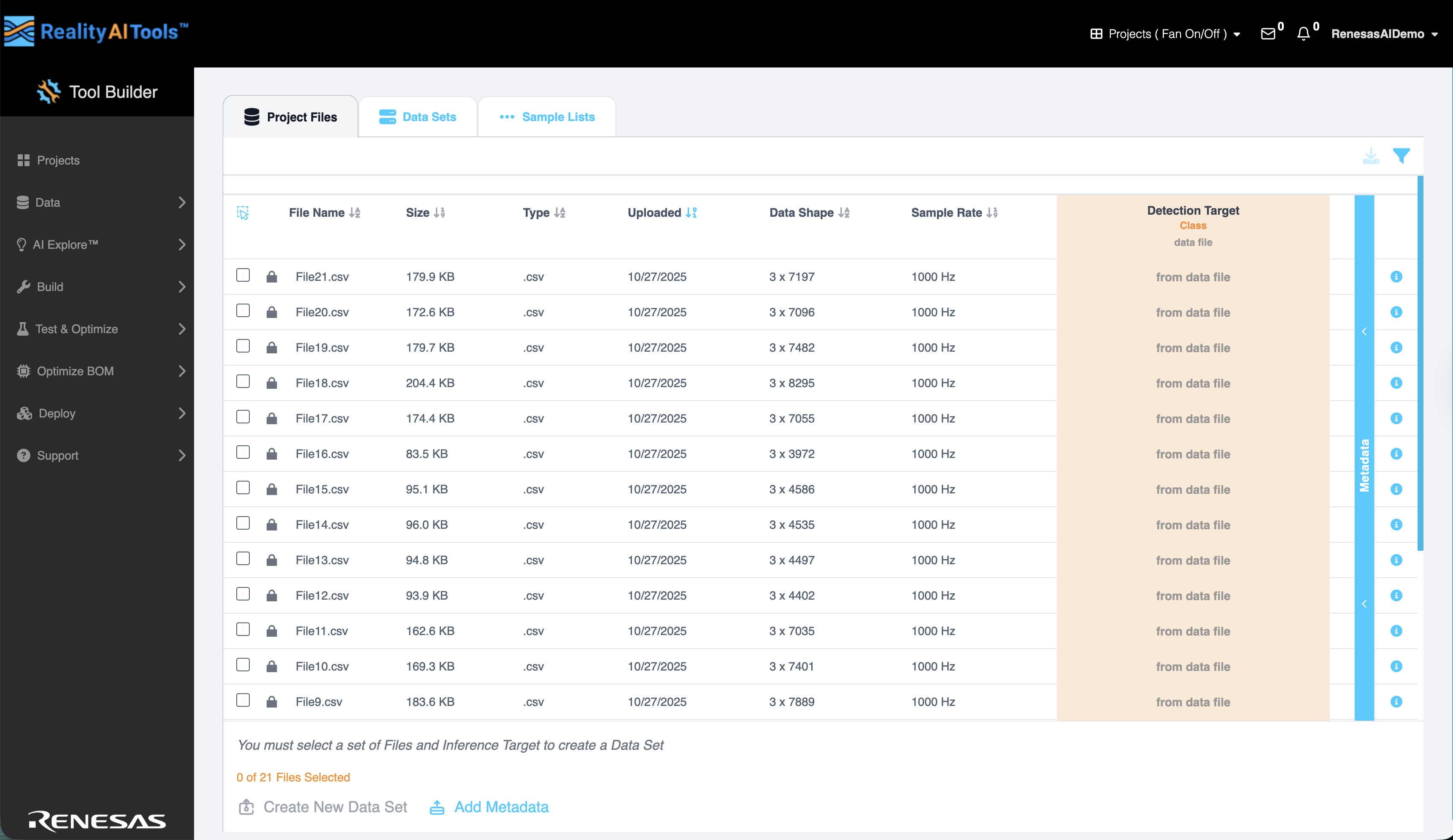
Project Files
项目文件 选项卡显示所有上传的数据文件及其相关详细信息:
- 文件名 (File Name) - 上传文件的名称。
- 大小 (Size) -
- 类型 (Type) -
- 已上传 (Uploaded) - 文件添加的日期。
- 数据形状 (Data Shape) - 文件的维度结构。
- 采样率 (Sample Rate) - 采集样本的速率。
- 推理目标 (Inference Target) - 要预测的标签或值。
- 元数据 (Metadata) - 链接到文件的任何附加描述性信息。
Adding Metadata to Project Files
元数据提供了可用于在训练期间过滤、标记或拆分数据的附加描述性字段。
- 在 项目文件 选项卡中,展开 元数据 部分以查看现有元数据。
- 选择 添加元数据 (Add Metadata)。添加元数据 对话框随即打开。
- 通过将 .csv 文件拖放到对话框中来上传它。此文件必须包含您希望与文件关联的元数据值。
导入后,元数据将链接到项目文件并显示在 元数据 部分中。
Configure Import Settings
在 添加元数据 窗口中,配置导入选项以匹配您的文件格式:
- 如果您的 CSV 包含标题行,请选中 标题行 (Label Row) 复选框。选中时,标题行将从导入的数据中排除。
- 从 分隔符 (Delimiter) 下拉菜单中,选择文件中使用的列分隔符。支持的分隔符包括 逗号 (,)、分号 (;)、空格 ( ) 和 制表符 (\t)。
- 如果您的文件使用逗号作为小数点(例如 1.234.567,89 而不是 1,234,567.89),请选中 欧洲小数 (European Decimals) 复选框。
- 选择 确认 (Confirm) 以完成导入并在 项目文件 选项卡中显示元数据。
Selecting Metadata Type
分配正确的元数据类型可确保准确的数据处理和模型训练。上传元数据文件后:
- 选择要配置的元数据列。
- 打开 选择元数据类型 (Select Metadata Type) 下拉菜单。
- 根据列内容选择以下类型之一:
- 目标类别 (Target Class) - 分类结果标签。
- 目标值 (Target Value) - 用于回归的数值目标。
- 分类元数据 (Categorical Metadata) - 描述性分类字段(例如,机器 ID)。
- 数值元数据 (Numerical Metadata) - 连续数值。
- 序列号/时间码 (Sequential #s / Time Code) - 有序数据,如帧或时间戳值。
- 日期和时间 (Date and Time)、仅日期 (Date Only) 或 仅时间 (Time Only) - 基于时间的字段。
- 忽略 (Ignore) - 从处理过程中排除列。
分配元数据类型后,它们将显示在 项目文件 选项卡中。
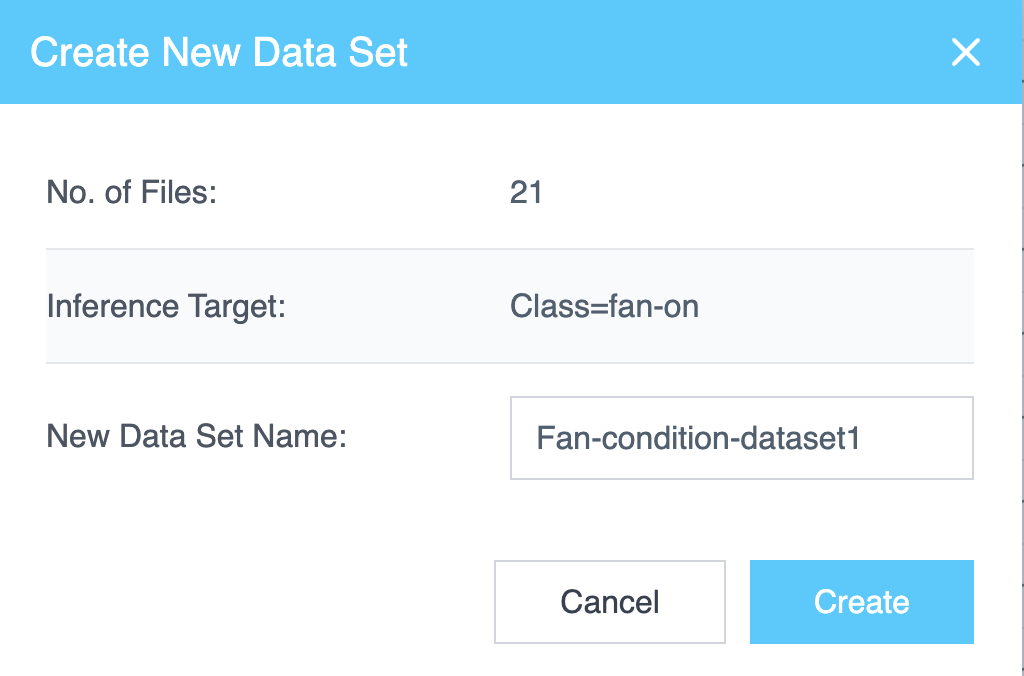
Creating a New Data Set
要创建数据集:
- 在 项目文件 选项卡中,选中要包含的每个文件旁边的复选框。可以选择多个文件。
- 选择 创建新数据集 (Create New Data Set)。
创建新数据集 对话框显示以下内容:
- 选定的文件数 (Number of Files Selected)
- 推理目标 (Inference Target)
- 输入 新数据集名称 (New Data Set Name) 的字段
输入名称并选择 创建 (Create) 以生成数据集。
如果数据集已存在,按钮将更改为 添加到数据集 (Add to Data Set)。选择它会打开现有数据集的列表,并带有 创建新数据集 选项。您可以将选定的文件添加到现有数据集或创建一个新数据集。
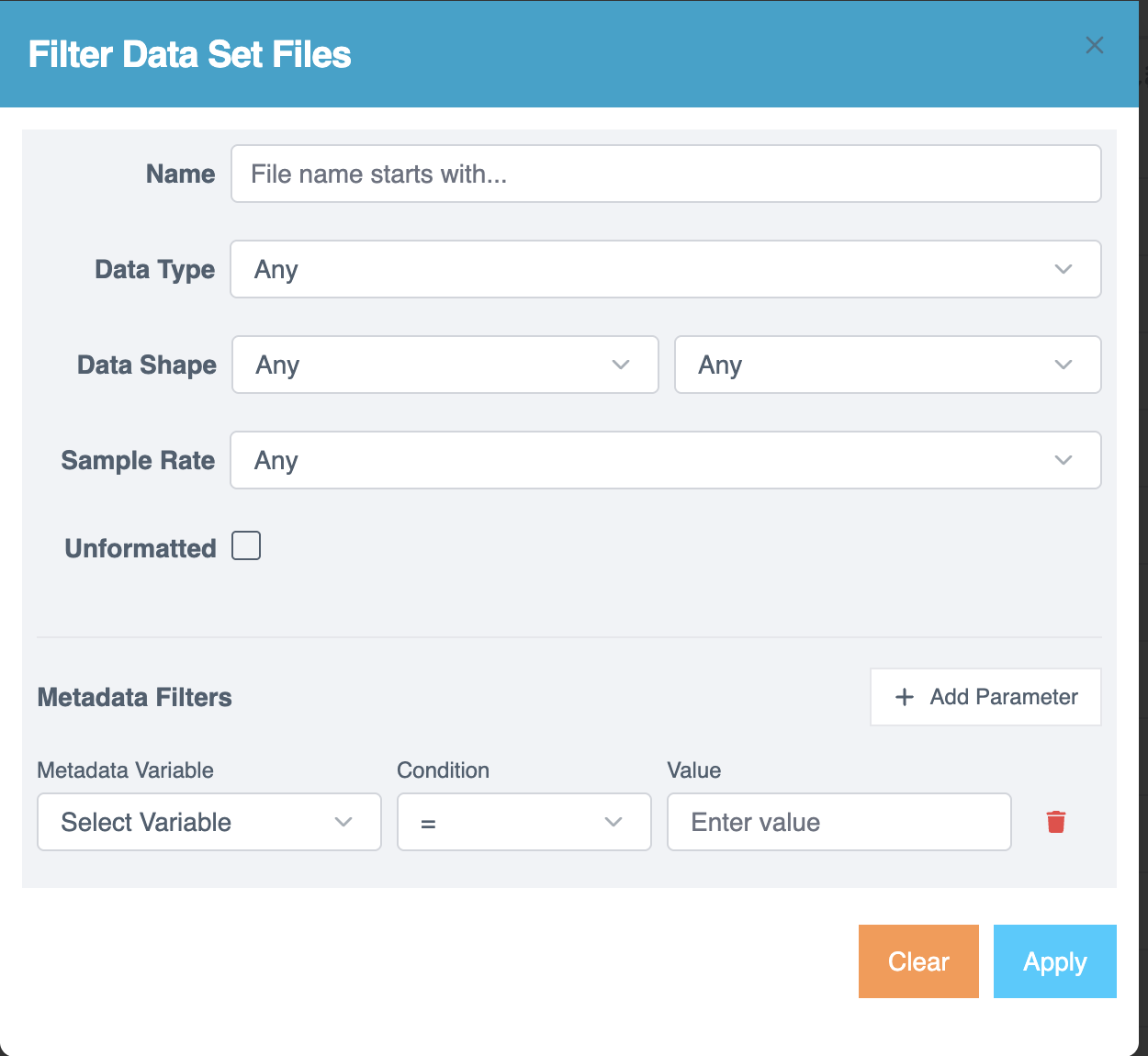
Filtering Project Files
使用过滤器快速定位文件:
- 选择 过滤器 (Filter) 图标打开 过滤数据集文件 (Filter Data Set Files) 页面。
- 根据需要应用过滤器:
- 名称 (Name) - 按文件名搜索。
- 数据类型 (Data Type) - 按数据类型过滤。
- 数据形状 (Data Shape) - 按数据形状缩小结果范围。
- 采样率 (Sample Rate) - 按采样率过滤。
- 未格式化 (Unformatted) - 识别尚未格式化的文件。
- 使用 元数据过滤器 (Metadata Filters) 部分进行高级过滤:
- 元数据变量 (Metadata Variable) - 选择一个变量。
- 条件 (Condition) - 选择运算符
(=, ≠, >, <, ≥, ≤, Contains, Starts with, Ends with, Regex)。 - 值 (Value) - 输入比较值。
- 选择 + 添加参数 (+ Add Parameter) 以包含多个条件。
- 选择 垃圾桶 图标以移除条件。
- 选择 应用 (Apply) 以过滤结果。
Data Sets
数据集 选项卡显示所有已创建的数据集以及以下详细信息:
- 名称 (Name)
- 创建日期 (Creation Date)
- 文件数量 (Number of Files)
- 数据形状 (Data Shape)
- 采样率 (Sample Rate)
- 总大小 (Total Size)
- 推理目标 (Inference Target)
选择数据集将显示详细的文件信息,包括文件名、大小、类型、上传日期、数据形状、采样率、推理目标和所选元数据。
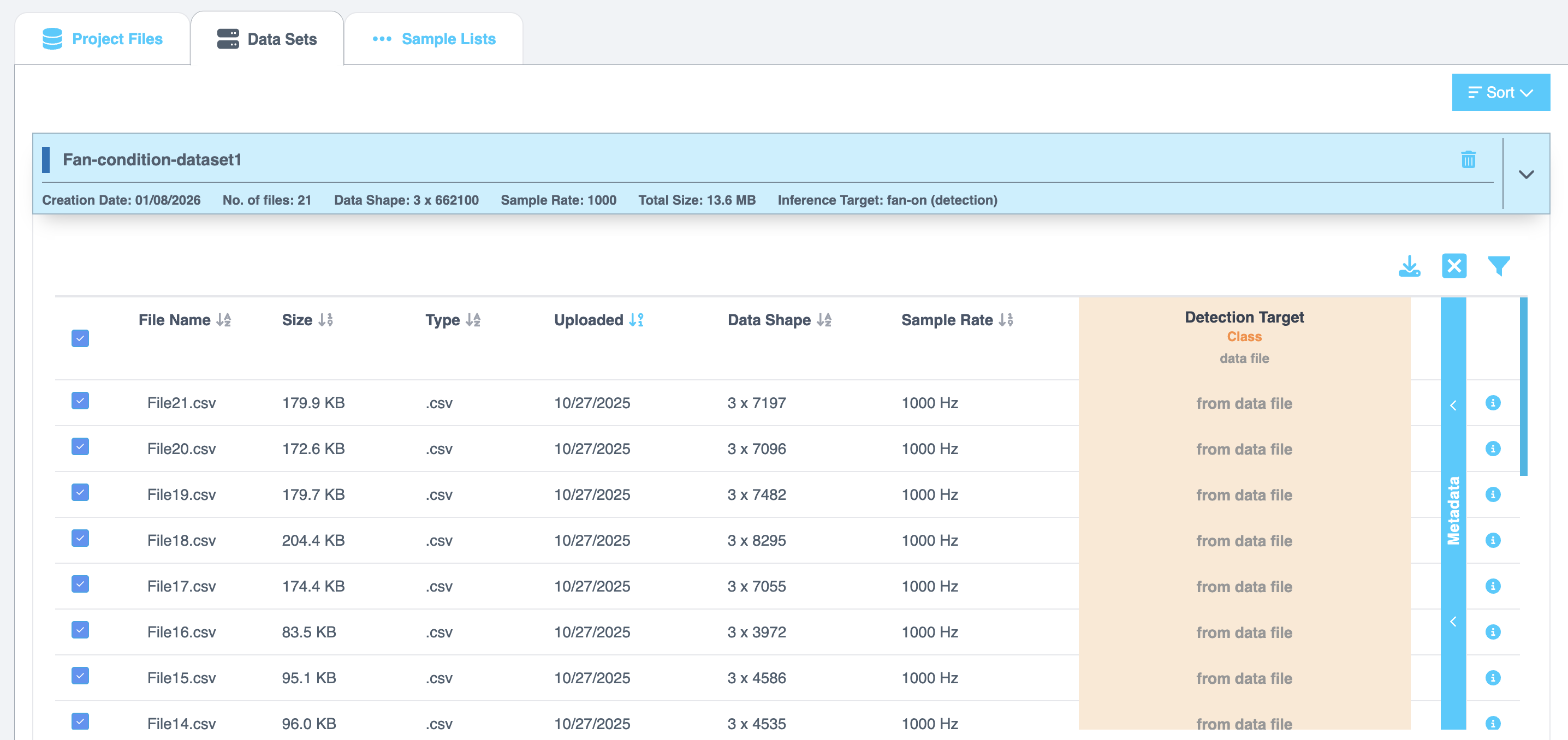
Additional Configuration Options
- 数据通道 (Data Channels) - 列出数据集中的所有通道。默认情况下,选择所有通道。使用复选框包含或排除通道。
- 选择 管理传感器组 (Manage Sensor Groups) 以打开传感器组对话框,您可以在其中:
- 添加、重命名或删除传感器组。
- 将数据通道分配给组。
- 保存更改以应用。
- 选择 管理传感器组 (Manage Sensor Groups) 以打开传感器组对话框,您可以在其中:
- 推理窗口 (Inference Window) - 显示:
- 采样率 (Hz)
- 窗口长度 (Window Length)(以数据点和毫秒显示)。您可以编辑这些值以配置分段。
- 推理目标 (Inference Target) - 显示推理目标变量的分布。直方图分为若干个箱 (bin),您可以使用上/下箭头调整箱的数量。计数和范围会动态更新。
选项卡底部显示摘要:
- 选定的文件总数
- 选定的通道总数
要继续,请选择 创建样本列表 (Create Sample List)。从以下选项中选择:
- 单个列表 (Single List)
- 随机拆分 (Random Split)
- 按元数据拆分 (Split by Metadata)
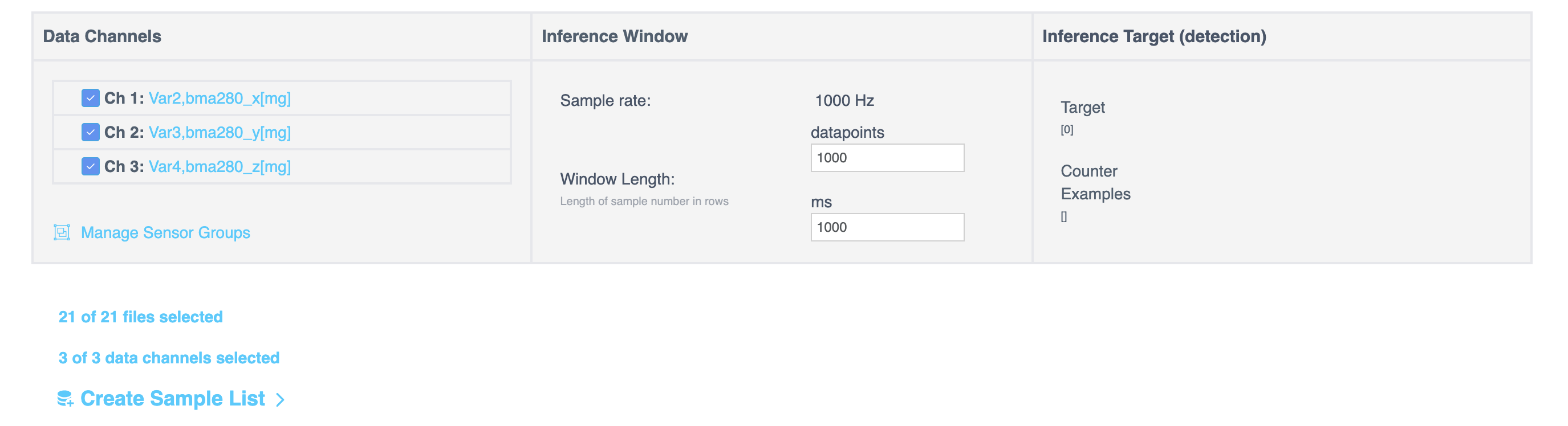
Creating a Segmented List
分段是将原始数据划分为更小的、统一的样本的过程。此步骤对于训练可在受限设备上实时运行的模型至关重要。
为什么要分段?
分段在生成针对资源受限环境(例如使用微控制器 (MCU) 的环境)部署进行优化的模型方面起着至关重要的作用。这些模型旨在快速高效地处理实时数据,通常在很小的时间窗口内(例如 1 秒、500 毫秒甚至更短的持续时间)。
在实际应用中,模型需要基于短而连续的数据流而不是长且不间断的记录来进行预测。为了在训练阶段复制这种情况,原始数据被分为更小的分段。然后使用这些分段来训练模型,使其能够学习并适应在实时生产环境中将遇到的数据类型。
这种方法确保模型在实时场景中有效执行,同时在有限的处理能力和内存限制下运行。
Creating a Single List
选择 单个列表 (Single List) 以创建一个分段列表。将文件分段为样本列表 (Segment Files to Sample List) 对话框随即打开。配置分段方法、窗口长度和其他选项,然后生成列表。
创建随机拆分
选择 随机拆分 (Random Split) 将数据划分为多个折 (fold) 进行训练和测试。对话框包括:
- 折数 (Folds):输入要创建的折数。折是将数据集拆分为多个子集时创建的分区之一。然后使用这些折来分配数据进行训练和测试,确保模型在数据集的不同部分上进行评估。
- 训练 (Train):输入用于训练的数据百分比。
- 测试 (Test):输入用于测试的数据百分比。
点击 继续 (Continue) 确认您的设置。接下来,将打开“将文件分段为样本列表”对话框。
Creating a Split by Metadata
选择 按元数据拆分 (Split by Metadata) 以基于元数据字段(如 源文件 (Source File)、目标值 (Target Value) 或用户定义的元数据)划分数据。所选元数据字段显示其分布。做出选择后,对话框将显示元数据字段、其值以及将创建的样本列表的数量。
点击 继续 (Continue) 确认您的设置。接下来,将打开“将文件分段为样本列表”对话框。
Segment Files to Sample List
此对话框配置如何将文件分段为样本列表。
| 选项 | 描述 |
|---|---|
| 文件名 (File names) | 要分段的文件的数量和名称 |
| 数据通道 (Data Channels) | 上一部分中选定的数据通道的数量和列表。 |
对话框根据所选的 分段方法 (Segmentation Method) 动态更新。您可以选择 滑动 CSV 窗口 (Sliding CSV Window) 或 能量触发 (Energy Triggered)。
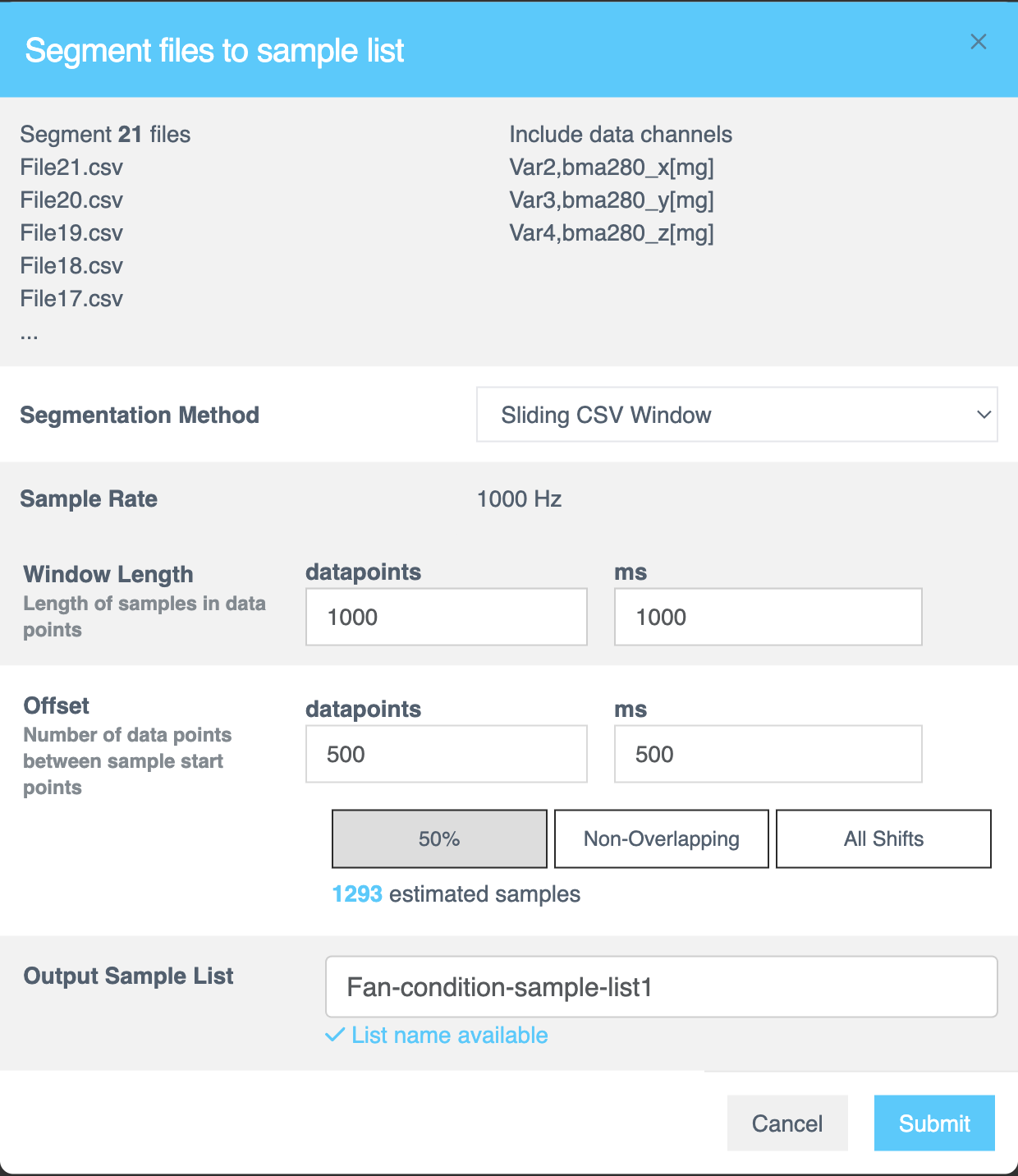
如果您选择滑动 CSV 窗口:
分段方法 | 滑动 CSV 窗口 (Sliding CSV Window) 方法使用逐步滑动窗口方法在整个文件中将 CSV 数据 [数值、基于文本或时间序列数据] 划分为更小的、可管理的样本,在每一步捕获数据,直到处理完整个文件。 |
|---|---|
采样率 (Sample Rate) | 显示将 CSV 文件解析为样本列表的固定采样率。此值在文件格式化期间是固定的。 |
窗口长度 (Window Length) | 窗口长度 决定了用于分段的决策窗口的大小。以行或毫秒 (ms) 为单位指定每个样本的长度。此值控制 AI 分析多少数据来对每个分段进行分类。 提示: 尝试不同的窗口长度以确定数据集的最佳配置。 |
偏移量 (Offset) | 偏移量 指定源文件中连续样本起始点之间的间隔。以数据点或毫秒 (ms) 为单位输入值,以定义解析器在创建新样本窗口之前移动的距离。您可以根据所做的选择查看估计的样本数。 |
50% 重叠 (50% Overlap) |
|
无重叠 (Non-Overlapping) |
|
所有移位 (All Shifts) |
|
输出样本列表 (Output Sample List) | 配置分段后,为分段样本列表提供一个名称。此字段为必填项。 |
如果您选择能量触发:
分段方法 | 能量触发 (Energy Triggered) 方法基于信号中检测到的能量事件对数据进行分段,仅在满足触发条件时捕获样本。这种方法特别适用于回归数据集(如音频信号),确保精确的事件驱动数据分析。 |
|---|---|
采样率 (Sample Rate) | 设置数据采样的频率。对于能量触发事件,这会自动设置为 100 Hz 以确保准确的数据捕获。无需手动输入。此项在文件格式化期间固定。 |
窗口长度 (Window Length) | 设置用于分析的一行中的样本数。帮助控制捕获数据的分辨率。直接输入值或使用向上和向下箭头进行调整。 |
触发通道 (Trigger Channel) | 确定触发检测的源。选项包括: |
| |
| |
| |
预处理 (Pre-Processing) | 配置数据归一化。选中 归一化 (Normalize) 复选框以启用此选项。这将缩放数据以确保统一性并改进样本之间的比较。 |
归零 (Zeroing) | 调整数据处理的归零方法。选项包括: |
无 (None):保留原始数据而不应用任何归零调整。 | |
去最小值 (DeMin):通过减去最小值来调整数据基线。 | |
去均值 (DeMean):通过减去均值将数据居中,确保分析时数据以零为中心。 | |
零窗口 (Zero Window) | 指定应用归零调整的持续时间。帮助管理所选窗口内的基线漂移。输入所需的值或使用向上和向下箭头进行调整。 |
滤波器 (Filter) | 设置数据处理的滤波器类型。选项包括: |
- 无 (None):不对数据应用滤波器。 | |
- 低通 (Low):应用低通滤波器以去除高频噪声,保留低频进行分析。 | |
- 带通 (Band):应用带通滤波器以隔离指定范围内的频率,去除该频带之外的频率。 | |
- 高通 (High):应用高通滤波器以去除低频噪声,保留高频进行分析。 | |
触发模式 (Trigger Mode) | 确定触发的模式。选项包括: |
- 幅度 (Amplitude):基于数据的幅度(信号强度)检测触发。 | |
- 正交叉 (+ Crossing):当信号穿过正阈值时触发。 | |
- 负交叉 (- Crossing):当信号穿过负阈值时触发。 | |
- RMS:使用均方根 (RMS) 值进行触发检测,关注信号中的总能量。 | |
- RMS 阶跃 (RMS Step):基于 RMS 值的阶跃变化触发。 | |
- RMS 阶跃比 (RMS Step Ratio):基于连续 RMS 阶跃变化的比率检测触发。 | |
- 峰值 RMS 比 (Peak to RMS Ratio):基于峰值信号值与其 RMS 值的比率触发,用于识别瞬态信号。 | |
- 差分 (Diff):基于连续数据点之间的差异检测触发。 | |
- 符号 (Sign):监控信号的符号(正或负)以进行触发检测。 | |
阈值 (Threshold) | 指定触发事件所需的最小信号电平。输入所需的值或使用向上和向下箭头。 |
跨度 (Span) | 定义触发检测的持续时间或范围。如果在触发模式中选择了幅度、差分或符号,则此字段不活动。 |
捕获选项 (Capture Options) | 配置用于捕获数据的预触发或最小间隔值: |
- 预触发 (Pre-Trigger):确定触发事件发生前捕获的数据量,有助于了解事件前的情况。 | |
- 最小间隔 (Min Separation):确保连续触发事件之间的最小间隔,以避免捕获冗余数据。 | |
限制每个文件的捕获数 (Limit Captures Per File) | 限制单个文件中存储的捕获数量,以管理文件大小并改进数据组织。选中复选框以激活此选项。 |
输出样本列表 (Output Sample List) | 配置分段后,为分段样本列表提供一个名称。此字段为必填项。 |
在右侧面板上,您可以预览所选文件。橙色线 代表触发点,蓝色线 代表捕获窗口。您可以查看多个通道以及支持缩放的概览。要放大,请在概览中选择并拖动一个区域;放大的视图将出现在上方的通道显示中。
选择 刷新预览 (Refresh Preview) 以更新视图。
注意
Explorer 层级有一个限制,即创建的分段列表包含的样本不得超过 7,000 个。
| 操作 | 描述 |
|---|---|
| 提交 (Submit) | 确认配置并完成该过程。 |
点击提交后,等待约 30 秒并刷新页面。刷新页面后,点击数据样本列表选项卡。点击该选项卡后,您应该能够看到已完成处理的列表。
注意
分段/分解此数据集需要 < 1 分钟。但是,分段的持续时间取决于数据集的大小。例如:1 GB 的文件可能需要 5-10 分钟来分段。
Sorting Data Sets
您可以使用右上角的 排序 (Sort) 选项对数据集进行排序。可用选项包括:
- 创建日期(旧 - 新)
- 创建日期(新 - 旧)
- 推理目标
- 采样率
- 数据形状
Sample Lists
本节说明如何使用 样本列表,这些列表是在执行 从所选内容分段列表 操作后生成的。这些列表以表格格式显示,包含以下详细信息:
| 字段 | 描述 |
|---|---|
| 列表名称 (List Name) | 样本列表的名称。 |
| 数据形状 (Data Shape) | 列表中数据的形状或维度。 |
| 采样率 (Sample Rate) | 采集样本的速率。 |
| N 样本 (N Samples) | 列表中的样本数。 |
| 目标范围 (Target Range) | 列表中的目标值范围。 |
| 已修改 (Modified) | 列表最后更新的日期和时间。 |
| 评论 (Comments) | 允许您添加有关数据样本列表的评论或注释。 |
| 信息 (Info) | 选择 信息 图标以查看详细信息,如名称、推理窗口、采样率、形状、偏移量、数据通道和文件名。 |
| 移除 (Remove) | 选择 垃圾桶 图标以删除样本列表。 |
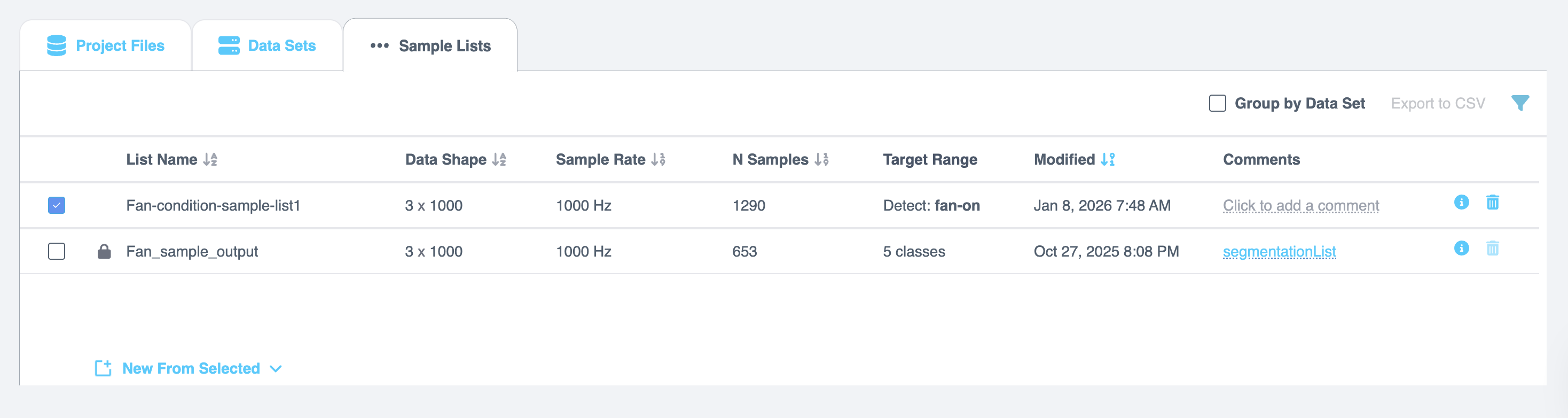
Managing Sample Lists
按数据集分组 (Group by Data Set)
选中 按数据集分组 复选框以按数据集组组织样本列表。
从选定行创建新列表
- 从样本列表中选择一行或多行。
- 打开 从所选新建 (New from selected) 下拉菜单。
- 选择以下选项之一:
- 复制样本列表 (Copy Sample List) - 创建所选列表的副本。
- 随机子集 (Random Subset) - 创建一个包含所选样本的随机子集的新列表。
- 连接 (Concatenate) - 将所选列表组合成单个列表。
复制样本列表
当您选择 复制样本列表 时,复制到新列表 窗口打开。
- 在 列表名称 字段中输入新名称。
- 选择 创建 (Create) 以生成复制的列表。
随机子集
当您选择 随机子集 时,随机子集到新列表 窗口打开。
- 在 列表名称 字段中输入新名称。
- 输入 每类样本数 (# of Samples per Class) 的值。此值必须小于样本总数。
- 选择 创建 (Create) 以生成新列表。
连接列表
当您选择 连接 时,连接列表 窗口打开并显示所选数据集的名称。
- 在 列表名称 字段中输入新名称。
- 选择 创建 (Create) 以生成连接的列表。
下载为 CSV
选择表格右上角的 下载 选项,将样本列表下载为 .csv 文件。
Filtering Lists
您可以过滤样本列表以查找特定项目。
- 点击 过滤器 (Filter) 图标打开 过滤列表 (Filter Lists) 页面。
- 使用提供的选项根据以下条件过滤列表:
- 名称 (Name): 按名称搜索列表。
- 创建日期 (Date Created): 选择日期范围或从预设选项中选择,如 今天、昨天、过去 7 天、过去 30 天、本月、上月 或 去年。选择 应用 确认。
- 数据形状 (Data Shape): 按数据形状过滤列表。
- 采样率 (Sample Rate): 根据采样率搜索列表。
- 在过滤字段中输入所需信息,然后点击 应用 (Apply) 以细化显示的列表。
Distribution
分布 部分提供从源文件创建的分段样本列表的可视化和表格表示。这些列表可用于 AI 探索、训练 或 测试。
样本列表中的每一行代表取自源文件流的固定长度的标记观测值。
查看分布
- 点击新创建的分段列表以打开其内容。
- 列表显示分段的数据块(也称为 窗口)。
- 会显示数据的直方图以帮助可视化分布。
- 使用 箱数 (# of Bins) 字段调整直方图的粒度。
- 增加或减少箱数会动态更新直方图。
- 类别 (Classes) 和 计数 (Count) 字段会自动调整以反映更改。
- 要查看样本列表的图形表示,请点击分布部分右上角的 图表图标。
- 图表将出现在弹出窗口中。
- 从左侧表格中选择一个样本列表。相应的图表将显示在右侧。
图表详情
图表弹出窗口提供详细信息,包括:
- 样本数
- 类别和样本计数
- 文件名
- 开始和结束时间(或者是值?)
- 目标类别
- 元数据字段
- 每个元数据字段的开始和结束值
当您在表格中选择一行时,列式图表将与概览部分一起出现。
多通道和缩放功能
- 您可以同时查看多个数据通道。
- 概览面板支持交互式缩放。
- 要放大,请在概览中点击并拖动所需部分。
- 放大区域显示在上方的通道图表中。
- 要重置,请点击 重置缩放 (Reset Zoom)。
::: info 注意 如果分段后直方图没有立即出现,请尝试刷新页面。 :::